3. Transact-SQL¶
Transact-SQL (又称 T-SQL),是在 Microsoft SQL Server 和 Sybase SQL Server 上的 ANSI SQL 实现,与 Oracle 的 PL/SQL 性质相近(不只是实现 ANSI SQL,也为自身数据库系统的特性提供实现支持),在 Microsoft SQL Server 和 Sybase Adaptive Server 中仍然被使用为核心的查询语言。
3.1. Transact-SQL 元素¶
| Transact-SQL 元素 | 说明 |
|---|---|
| 标识符 | 表、视图、列、数据库和服务器等对象的名称。 |
| 数据类型 | 定义数据对象(如列、变量和参数)所包含的数据的类型。大多数 Transact-SQL 语句并不显式引用数据类型,但它们的结果受语句中所引用对象的数据类型之间的交互操作影响。 |
| 常量 | 代表特定数据类型的符号。 |
| 函数 | 语法元素,可以接受零个、一个或多个输入值,并返回一个标量值或表格形式的一组值。示例包括将多个值相加的 SUM 函数、确定两个日期之间相差多少个时间单位的 DATEDIFF 函数、获取 Microsoft SQL Server 实例名称的 @@SERVERNAME 函数或在远程服务器上执行 Transact-SQL 语句并检索结果集的 OPENQUERY 函数。 |
| 表达式 | SQL Server 可以解析为单个值的语法单位。表达式的示例包括常量、返回单值的函数、列或变量的引用。 |
| 表达式中的运算符 | 与一个或多个简单表达式一起使用,构造一个更为复杂的表达式。例如,表达式 PriceColumn * 1.1 中的乘号 (*) 使价格提高百分之十。 | | 注释 | 插入到 Transact-SQL 语句或脚本中、用于解释语句作用的文本段。SQL Server 不执行注释。 | | 保留关键字 | 保留下来供 SQL Server 使用的词,不应用作数据库中的对象名。 | |
3.2. Transact-SQL标识符¶
Microsoft SQL Server 中的所有内容都可以有标识符。服务器、数据库和数据库对象(例如表、视图、列、索引、触发器、过程、约束及规则等)都可以有标识符。大多数对象要求有标识符,但对有些对象(例如约束),标识符是可选的。
3.2.1. 标识符的种类¶
有两类标识符:
- 常规标识符 符合标识符的格式规则。在 Transact-SQL 语句中使用常规标识符时不用将其分隔开。
SELECT *
FROM TableX
WHERE KeyCol = 1024
- 分隔标识符 包含在双引号 (“) 或者方括号 ([ ]) 内。不分隔符合标识符格式规则的标识符。例如:
SELECT * FROM [TableX] --用不用分隔符都可以
WHERE [KeyCol] = 1024 --用不用分隔符都可以
在 Transact-SQL 语句中,必须对不符合所有标识符规则的标识符进行分隔。例如:
SELECT * FROM [My Table] --My Table之间包含空格,因此必须包含分隔标识符
WHERE [order] = 10 --关键字必须包含分隔符
常规标识符和分隔标识符包含的字符数必须在 1 到 128 之间。对于本地临时表,标识符最多可以有 116 个字符。
3.2.2. 常规标识符规则¶
常规标识符格式规则取决于数据库兼容级别。该级别可以使用 ALTER DATABASE 设置。当兼容级别为 100 时,下列规则适用:
- 第一个字符必须是下列字符之一:
Unicode 标准 3.2 所定义的字母。Unicode 中定义的字母包括拉丁字符 a-z 和 A-Z,以及来自其他语言的字母字符。
下划线 (_)、at 符号 (@) 或数字符号 (#)。
在 SQL Server 中,某些位于标识符开头位置的符号具有特殊意义。以 at 符号开头的常规标识符始终表示局部变量或参数,并且不能用作任何其他类型的对象的名称。以一个数字符号开头的标识符表示临时表或过程。以两个数字符号 (##) 开头的标识符表示全局临时对象。虽然数字符号或两个数字符号字符可用作其他类型对象名的开头,但是不建议这样做。
某些 Transact-SQL 函数的名称以两个 at 符号 (@@) 开头。为了避免与这些函数混淆,不应使用以 @@ 开头的名称。
- 后续字符可以包括:
- 如 Unicode 标准 3.2 中所定义的字母。
- 基本拉丁字符或其他国家/地区字符中的十进制数字。
- at 符号、美元符号 ($)、数字符号或下划线。
- 标识符一定不能是 Transact-SQL 保留字。SQL Server 可以保留大写形式和小写形式的保留字。
- 不允许嵌入空格或其他特殊字符。
- 不允许使用增补字符。
在 Transact-SQL 语句中使用标识符时,不符合这些规则的标识符必须由双引号或括号分隔。
3.3. Transact-SQL 数据类型¶
包含数据的对象都有一个相关联的数据类型,它定义对象所能包含的数据种类,例如字符、整数或二进制。下列对象具有数据类型:
- 表和视图中的列。
- 存储过程中的参数。
- 变量。
- 返回一个或多个特定数据类型数据值的 Transact-SQL 函数。
- 具有返回代码(始终为 integer 数据类型)的存储过程。
为对象分配数据类型时可以为对象定义四个属性:
- 对象包含的数据种类。
- 所存储值的长度或大小。
- 数值的精度(仅适用于数字数据类型)。
- 数值的小数位数(仅适用于数字数据类型)。
3.3.1. 二进制数据¶
binary 和 varbinary 数据类型存储位串。尽管字符数据是根据 SQL Server 代码页进行解释的,但 binary 和 varbinary 数据仅是位流。
- binary [ ( n ) ] 长度为 n 字节的固定长度二进制数据,其中 n 是从 1 到 8,000 的值。存储大小为 n 字节。
- varbinary [ ( n | max) ] 可变长度二进制数据。n 可以是从 1 到 8000 之间的值。max 指示最大存储大小为 2^31-1 字节。存储大小为所输入数据的实际长度 + 2 个字节。所输入数据的长度可以是 0 字节。varbinary 的 ANSI SQL 同义词为 binary varying。
二进制常量以 0x(一个零和小写字母 x)开始,后跟位模式的十六进制表示形式。例如,0x2A 表示十六进制值 2A,它等于十进制值 42 或单字节位模式 00101010。
存储十六进制值 [如安全标识号 (SID)、GUID(使用 uniqueidentifier 数据类型)或可以用十六进制方式存储的复杂数字时,使用二进制数据。
3.3.2. 字符串¶
char 和 varchar 数据类型存储由以下字符组成的数据:
- 大写字符或小写字符。例如,a、b 和 C。
- 数字。例如,1、2 和 3。
- 特殊字符。例如,at 符号 (@)、“与”符号 (&) 和感叹号 (!)。
使用方式:
- char [ ( n ) ] 固定长度,非 Unicode 字符串数据。n 定义字符串长度,取值范围为 1 至 8,000。存储大小为 n 字节。当排序规则代码页使用双字节字符时,存储大小仍然为 n 个字节。根据字符串的不同,n 个字节的存储大小可能小于为 n 指定的值。char 的 ISO 同义词为 character。
- varchar [ ( n | max ) ] 可变长度,非 Unicode 字符串数据。n 定义字符串长度,取值范围为 1 至 8,000。max 指示最大存储大小是 2^31-1 个字节 (2 GB)。存储大小为输入的实际数据长度 + 2 个字节。varchar 的 ISO 同义词为 char varying 或 character varying。
varchar 数据可以有两种形式。varchar 数据的最大字符长度可以是指定的。例如,varchar(6) 指示此数据类型最多存储六位字符;它也可以是 varchar(max), 形式的,即此数据类型可存储的最大字符数可达 2^31。
每个 char 和 varchar 数据值都具有排序规则。排序规则定义属性,如用于表示每个字符的位模式、比较规则以及是否区分大小写或重音。每个数据库有默认排序规则。当定义列或指定常量时,除非使用 COLLATE 子句指派特定的排序规则,否则将为它们指派数据库的默认排序规则。当组合或比较两个具有不同排序规则的 char 或 varchar 值时,根据排序规则的优先规则来确定操作所使用的排序规则。
字符常量必须包括在单引号 (‘) 或双引号 (“) 中。建议用单引号括住字符常量。
3.3.3. Unicode 字符串¶
Unicode 规格为全球商业领域中广泛使用的大部分字符定义了一个单一编码方案。所有的计算机都用单一的 Unicode 规格将 Unicode 数据中的位模式一致地转换成字符。这保证了同一个位模式在所有的计算机上总是转换成同一个字符。数据可以随意地从一个数据库或计算机传送到另一个数据库或计算机,而不用担心接收系统是否会错误地转换位模式。
每个 Microsoft SQL Server 排序规则都有一个代码页,该代码页定义表示 char、varchar 和 text 值中每个字符的位模式。可为个别的列和字符常量分配不同的代码页。
Unicode 规格通过采用两个字节编码每个字符使这个问题迎刃而解。转换最通用商业语言的单一规格具有足够多的 2 字节的模式 (65536)。因为所有的 Unicode 系统均一致地采用同样的位模式来表示所有的字符,所以当从一个系统转到另一个系统时,将不会存在未正确转换字符的问题。通过在整个系统中使用 Unicode 数据类型,可尽量减少字符转换问题。
在 SQL Server 中,下列数据类型支持 Unicode 数据:
- nchar
- nvarchar
- ntext
字符串数据类型(nchar 长度固定或 nvarchar 长度可变)和 Unicode 数据使用 UNICODE UCS-2 字符集。
- nchar [ ( n ) ] 固定长度,Unicode 字符串数据。n 定义字符串长度,取值范围为 1 至 4,000。存储大小为 n 字节的两倍。当排序规则代码页使用双字节字符时,存储大小仍然为 n 个字节。根据字符串的不同,n 个字节的存储大小可能小于为 n 指定的值。nchar 的 ISO 同义词为 national char 和 national character。
- nvarchar [ ( n | max ) ] 可变长度,Unicode 字符串数据。n 定义字符串长度,取值范围为 1 至 4,000。max 指示最大存储大小是 2^31-1 个字节 (2 GB)。存储大小(以字节为单位)是所输入数据实际长度的两倍 + 2 个字节。nvarchar 的 ISO 同义词为 national char varying 和 national character varying。
除下列情况外,nchar、nvarchar 和 ntext 的使用分别与 char、varchar 和 text 的使用相同:
- Unicode 支持更大范围的字符。
- 存储 Unicode 字符需要更大的空间。
- nchar 列的最大大小为 4,000 个字符,与 char 和 varchar 不同,它们为 8,000 个字符。
- 使用最大说明符,nvarchar 列的最大大小为 2^31-1 字节。
- Unicode 常量以 N 开头指定:N’A Unicode string’。
- 所有 Unicode 数据使用由 Unicode 标准定义的字符集。用于 Unicode 列的 Unicode 排序规则以下列属性为基础:区分大小写、区分重音、区分假名、区分全半角和二进制。
3.3.4. Text和Image¶
Microsoft SQL Server 将超过 8,000 个字节的字符串和大于 8,000 个字节的二进制数据分别存储为名为 text 和 image 的特殊数据类型。超过 4,000 个字符的 Unicode 字符串存储为 ntext 数据类型。
例如,您需要将一个大型客户信息文本文件 (.txt) 导入 SQL Server 数据库。应将这些数据作为一个数据块存储起来,而不是集成到数据表的多个列中。为此,可以创建一个 text 数据类型的列。但是,如果必须存储公司徽标,它们当前存储为标记图像文件格式 (TIFF) 图像 (.tif) 且每个图像的大小为 10 KB,则可以创建一个 image 数据类型的列。
3.3.5. 整数¶
| 数据类型 | 范围 | 存储 |
|---|---|---|
| bigint | -2^63 (-9,223,372,036,854,775,808) 到 2^63-1 (9,223,372,036,854,775,807) | 8 字节 |
| int | -2^31 (-2,147,483,648) 到 2^31-1 (2,147,483,647) | 4 字节 |
| smallint | -2^15 (-32,768) 到 2^15-1 (32,767) | 2 字节 |
| tinyint | 0 到 255 | 1 字节 |
在数据类型优先次序表中,bigint 介于 smallmoney 和 int 之间。
尽管 SQL Server 有时会将 tinyint 或 smallint 值提升为 int 数据类型,但不会自动将 tinyint、smallint 或 int 值提升为 bigint 数据类型。除非明确说明,否则那些接受 int 表达式作为其参数的函数、语句和系统存储过程都不会改变,从而不会支持将 bigint 表达式隐式转换为这些参数,只有当参数表达式为 bigint 数据类型时,函数才返回 bigint。
3.3.6. decimal、numeric、float和real¶
精度是数字中的数字个数。小数位数是数中小数点右边的数字个数。例如,数 123.45 的精度是 5,小数位数是 2。
decimal 数据类型最多可以存储 38 个数字,所有这些数字均可位于小数点后面。decimal 数据类型存储精确的数字表示形式,存储值没有近似值。
定义 decimal 列、变量和参数的两种属性为:
- p
指定精度或对象能够支持的数字个数。
- s
指定可以放在小数点右边的小数位数或数字个数。
p 和 s 必须遵守规则:0 <= s <= p <= 38。
- decimal[ (p[ ,s] )] 和 numeric[ (p[ ,s] )] 固定精度和小数位数。使用最大精度时,有效值从 - 10^38 +1 到 10^38 - 1。decimal 的 ISO 同义词为 dec 和 dec(p, s)。numeric 在功能上等价于 decimal。
- p(精度) 最多可以存储的十进制数字的总位数,包括小数点左边和右边的位数。该精度必须是从 1 到最大精度 38 之间的值。默认精度为 18。
- s (小数位数) 小数点右边可以存储的十进制数字的最大位数。小数位数必须是从 0 到 p 之间的值。仅在指定精度后才可以指定小数位数。默认的小数位数为 0;因此,0 <= s <= p。最大存储大小基于精度而变化。
| 精度 | 存储字节数 |
|---|---|
| 1 - 9 | 5 |
| 10-19 | 9 |
| 20-28 | 13 |
| 29-38 | 17 |
在 SQL Server 中,numeric 和 decimal 数据类型的默认最大精度为 38。在 SQL Server 早期版本中,默认最大精度为 28。numeric 的功能等同于 decimal 数据类型。
float 和 real 数据类型被称为近似数据类型。float 和 real 的使用遵循有关近似数值数据类型的 IEEE 754 规范。
| 数据类型 | 范围 | 存储 |
|---|---|---|
| float | -1.79E + 308 至 -2.23E - 308、0 以及 2.23E - 308 至 1.79E + 308 | 取决于 n 的值 |
| real | -3.40E + 38 至 -1.18E - 38、0 以及 1.18E - 38 至 3.40E + 38 | 4 字节 |
其中 n 为用于存储 float 数值尾数的位数(以科学记数法表示)。 如果 1**<=n<=**24,则将 n 视为 24。 如果 25**<=n<=**53,则将 n 视为 53。n的默认值为53。real 的 ISO 同义词为 float(24)。
| n的值 | 精度 | 存储 |
|---|---|---|
| 1-24 | 7位数 | 4 字节 |
| 25-53 | 15位数 | 8 字节 |
近似数值数据类型并不存储为许多数字指定的精确值,它们只储存这些值的最近似值。 在很多应用程序中,指定值与存储的近似值之间的微小差异并不明显。但有时这些差异也较明显。
在 WHERE 子句搜索条件(特别是 = 和 <> 运算符)中,应避免使用 float 列或 real 列。float 列和 real 列最好只限于 > 比较或 < 比较。
IEEE 754 规范提供四种舍入模式:舍入到最近、向上舍入、向下舍入以及舍入到零。Microsoft SQL Server 使用向上舍入。所有的数值都必须精确到确定的精度,但会产生微小的浮点值差异。因为浮点数字的二进制表示法可以采用很多合法舍入规则中的任意一条,因此我们不可能可靠地量化浮点值。
3.3.7. 货币数据¶
Microsoft SQL Server 使用以下两种数据类型存储货币数据或货币值:money 和 smallmoney。这些数据类型可以使用下列任意一种货币符号。

代表 货币或货币值 的数据类型。
| 数据类型 | 范围 | 存储 |
|---|---|---|
| money | -922,337,203,685,477.5808 到 922,337,203,685,477.5807 | 8 字节 |
| smallmoney | -214,748.3648 到 214,748.3647 | 4 字节 |
money 和 smallmoney 数据类型精确到它们所代表的货币单位的万分之一。
3.3.8. 日期和时间数据¶
下表列出了 Transact-SQL 的日期和时间数据类型。
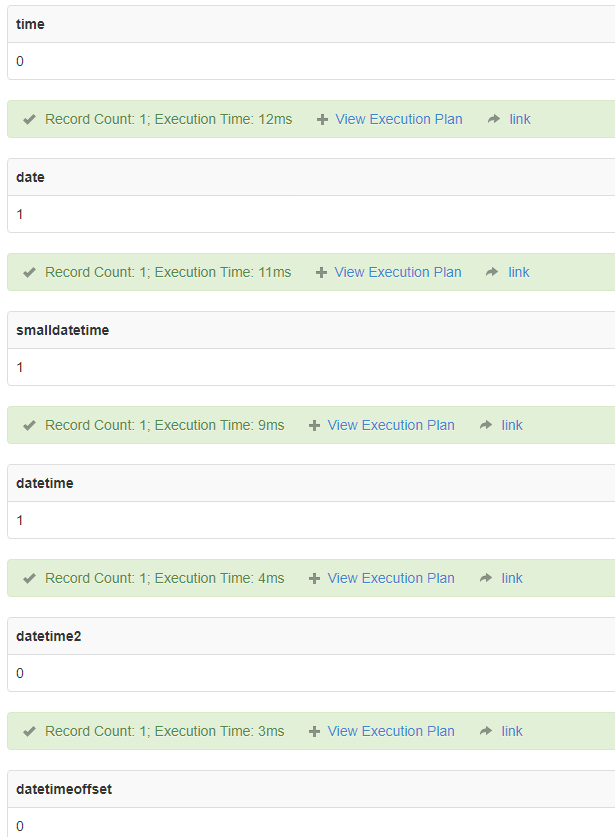
| 数据类型 | 格式 | 范围 | 精确度 | 存储使用字节 |
|---|---|---|---|---|
| time | hh:mm:ss[.nnnnnnn] | 00:00:00.0000000 到 23:59:59.9999999 | 100 纳秒 | 3 到 5 |
| date | YYYY-MM-DD | 0001-01-01 到 9999-12-31 | 1 天 | 3 |
| smalldatetime | YYYY-MM-DD hh:mm:ss | 1900-01-01 到 2079-06-06 | 1 分钟 | 4 |
| datetime | YYYY-MM-DD hh:mm:ss[.nnn] | 1753-01-01 到 9999-12-31 | 0.00333 秒 | 8 |
| datetime2 | YYYY-MM-DD hh:mm:ss[.nnnnnnn] | 0001-01-01 00:00:00.0000000 到 9999-12-31 23:59:59.9999999 | 100 纳秒 | 6 到 8 |
| datetimeoffset | YYYY-MM-DD hh:mm:ss[.nnnnnnn] [+|-]hh:mm | 0001-01-01 00:00:00.0000000 到 9999-12-31 23:59:59.9999999(以 UTC 时间表示) | 100 纳秒 | 8 到 10 |
所有日期和时间数据类型都支持关系运算符(<、<=、>、>=、<>)、比较运算符(=、<、<=、>、>=、<>、!<、!>)以及逻辑运算符和布尔谓词(IS NULL、IS NOT NULL、IN、BETWEEN、EXISTS、NOT EXISTS 和 LIKE)。
3.3.9. 数据类型转换¶
可以按以下方案转换数据类型:
- 当一个对象的数据移到另一个对象,或两个对象之间的数据进行比较或组合时,数据可能需要从一个对象的数据类型转换为另一个对象的数据类型。
- 将 Transact-SQL 结果列、返回代码或输出参数中的数据移到某个程序变量中时,必须将这些数据从 SQL Server 系统数据类型转换成该变量的数据类型。
可以隐式或显式转换数据类型:
- 隐式转换对用户不可见。
SQL Server 会自动将数据从一种数据类型转换为另一种数据类型。例如,将 smallint 与 int 进行比较时,在比较之前 smallint 会被隐式转换为 int。请注意,查询优化器可能生成一个查询计划来在任意时间执行此转换。
- 显式转换使用 CAST 或 CONVERT 函数。
如果希望 Transact-SQL 程序代码符合 ISO 标准,请使用 CAST 而不要使用 CONVERT。如果要利用 CONVERT 中的样式功能,请使用 CONVERT 而不要使用 CAST。
3.3.10. uniqueidentifier¶
uniqueidentifier 数据类型可存储 16 字节的二进制值,其作用与全局唯一标识符 (GUID) 一样。GUID 是唯一的二进制数;世界上的任何两台计算机都不会生成重复的 GUID 值。GUID 主要用于在拥有多个节点、多台计算机的网络中,分配必须具有唯一性的标识符。
uniqueidentifier 列的 GUID 值通常通过下列方式之一获取:
- 在 Transact-SQL 语句、批处理或脚本中调用 NEWID 函数。
- 在应用程序代码中,调用返回 GUID 的应用程序 API 函数或方法。
Transact-SQL NEWID 函数以及应用程序 API 函数和方法用它们的网卡的标识号加上 CPU 时钟的唯一编号来生成新的 uniqueidentifier 值。每个网卡都有唯一的标识号。NEWID 返回的 uniqueidentifier 值是通过使用服务器上的网卡而生成的。应用程序 API 函数和方法返回的 uniqueidentifier 值是通过使用客户端中的网卡而生成的。
uniqueidentifier 值通常不定义为常量。您可以按下列方式指定 uniqueidentifier 常量:
- 字符串格式: ‘6F9619FF-8B86-D011-B42D-00C04FC964FF’
- 二进制格式: 0xff19966f868b11d0b42d00c04fc964ff
uniqueidentifier 数据类型具有下列缺点:
- 值长且难懂。这使用户难以正确键入它们,并且更难记住。
- 这些值是随机的,而且它们不支持任何使其对用户更有意义的模式。
- 也没有任何方式可以决定生成 uniqueidentifier 值的顺序。它们不适用于那些依赖递增的键值的现有应用程序。
- 当 uniqueidentifier 为 16 字节时,其数据类型比其他数据类型(例如 4 字节的整数)大。这意味着使用 uniqueidentifier 键生成索引的速度相对慢于使用 int 键生成索引的速度。
3.3.11. XML数据¶
可以创建 xml 数据类型的变量和列。xml 数据类型有自己的 XML 数据类型方法。
| XML方法 | 说明 |
|---|---|
| query() 方法(xml 数据类型) | 说明如何使用 query() 方法查询 XML 实例。 |
| value() 方法(xml 数据类型) | 说明如何使用 value() 方法从 XML 实例中检索 SQL 类型的值。 |
| exist() 方法(xml 数据类型) | 说明如何使用 exist() 方法确定查询是否返回非空结果。 |
| modify() 方法(xml 数据类型) | 说明如何使用 modify() 方法指定 XML Data Modification Language (XML DML) 语句以执行更新。 |
| nodes() 方法(xml 数据类型) | 说明如何使用 nodes() 方法将 XML 拆分到多行中,从而将 XML 文档的组成部分传播到行集中。 |
| 在 XML 数据内部绑定关系数据 | 说明如何在 XML 中绑定非 XML 数据。 |
| xml 数据类型方法的使用准则 | 说明使用 xml 数据类型方法的指导原则。 |
可以对 xml 数据类型的列和变量中存储的 XML 数据指定 XQuery 语言。
3.3.12. timestamp和rowversion¶
每个数据库都有一个计数器,当对数据库中包含 rowversion 列的表执行插入或更新操作时,该计数器值就会增加。此计数器是数据库行版本。这可以跟踪数据库内的相对时间,而不是时钟相关联的实际时间。一个表只能有一个 rowversion 列。
每次修改或插入包含 rowversion 列的行时,就会在 rowversion 列中插入经过增量的数据库行版本值。这一属性使 rowversion 列不适合作为键使用,尤其是不能作为主键使用。对行的任何更新都会更改行版本值,从而更改键值。如果该列属于主键,那么旧的键值将无效,进而引用该旧值的外键也将不再有效。如果该表在动态游标中引用,则所有更新均会更改游标中行的位置。如果该列属于索引键,则对数据行的所有更新还将导致索引更新。
timestamp 的数据类型为 rowversion 数据类型的同义词,并具有数据类型同义词的行为。在 DDL 语句,请尽量使用 rowversion 而不是 timestamp。
3.3.13. cursor¶
cursor是变量或存储过程 OUTPUT 参数的一种数据类型,这些参数包含对游标的引用。使用 cursor数据类型创建的变量可以为空。
有些操作可以引用那些带有 cursor 数据类型的变量和参数,这些操作包括:
- DECLARE @local_variable 和 SET @local_variable 语句。
- OPEN、FETCH、CLOSE 及 DEALLOCATE 游标语句。
- 存储过程输出参数。
- CURSOR_STATUS 函数。
- sp_cursor_list、sp_describe_cursor、sp_describe_cursor_tables 以及 sp_describe_cursor_columns 系统存储过程。
3.3.14. table¶
table 是一种特殊的数据类型,用于存储结果集以进行后续处理。主要用于临时存储一组作为表值函数的结果集返回的行。可将函数和变量声明为 table 类型。table 变量可用于函数、存储过程和批处理中。
3.3.15. sql_variant¶
sql_variant用于存储 SQL Server 支持的各种数据类型的值。sql_variant 可以用在列、参数、变量和用户定义函数的返回值中。sql_variant 使这些数据库对象能够支持其他数据类型的值。
最大长度可以是 8016 个字节。这包括基类型信息和基类型值。实际基类型值的最大长度是 8,000 个字节。
3.4. Transact-SQL 函数¶
SQL Server 提供了可用于执行特定操作的内置函数。具体内置函数
| 函数类别 | 说明 |
|---|---|
| 聚合函数 | 执行的操作是将多个值合并为一个值。如 COUNT、SUM、MIN 和 MAX。 |
| 分析函数 | 分析函数基于一组行计算聚合值。 但是,与聚合函数不同, 分析函数可能针对每个组返回多行。 可以使用分析函数来计算移动平均线、运行总计、百分比 或一个组内的前 N 个结果。 |
| 配置函数 | 是一种标量函数,可返回有关配置设置的信息。 |
| 加密函数 (Transact-SQL) | 支持加密、解密、数字签名和数字签名验证。 |
| 游标函数 | 返回有关游标状态的信息。 |
| 日期和时间函数 | 可以更改日期和时间的值。 |
| 数学函数 | 执行三角、几何和其他数字运算。 |
| 元数据函数 | 返回数据库和数据库对象的属性信息。 |
| 排名函数 | 是一种非确定性函数,可以返回分区中每一行的排名值。 |
| 行集函数 (Transact-SQL) | 返回可在 Transact-SQL 语句中表引用所在位置使用的行集。 |
| 安全函数 | 返回有关用户和角色的信息。 |
| 字符串函数 | 可更改 char、varchar、nchar、nvarchar、binary 和 varbinary 的值。 |
| 系统函数 | 对系统级的各种选项和对象进行操作或报告。 |
| 系统统计函数 (Transact-SQL) | 返回有关 SQL Server 性能的信息。 |
| 文本和图像函数 | 可更改 text 和 image 的值。 |
3.4.1. 系统函数¶
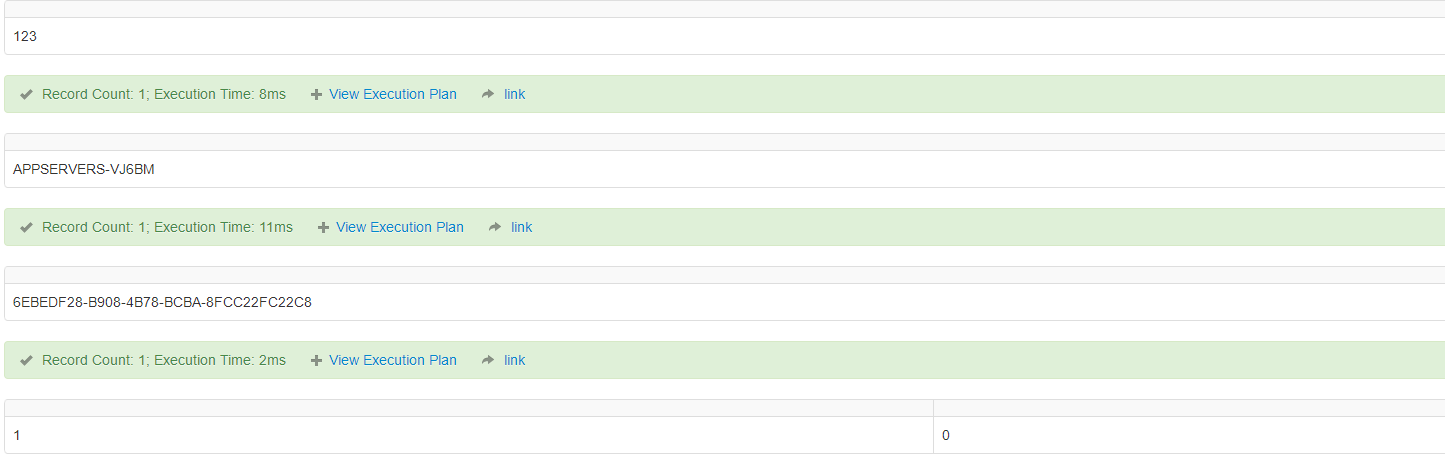
-- 返回工作站标识号,是连接到 SQL Server的客户端计算机上的应用程序的进程 ID (PID)
SELECT HOST_ID();
-- 返回工作站名
SELECT HOST_NAME();
-- 创建 uniqueidentifier 类型的唯一值
SELECT NEWID();
-- 确定表达式是否为有效的数值类型;ISNUMERIC ( expression )
SELECT distinct
ISNUMERIC(sid),ISNUMERIC(ssex)
from Student
-- 使用指定的替换值替换 NULL。
-- ISNULL ( check_expression , replacement_value )
3.4.1.1. CAST 和 CONVERT¶
CAST 和 CONVERT函数是将一种数据类型的表达式转换为另一种数据类型的表达式。
-- CAST()语法:
CAST ( expression AS data_type [ ( length ) ] )
-- CONVERT()语法:
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
- expression 任何有效的 表达式 。
- data_type 目标数据类型。这包括 xml、bigint 和 sql_variant。不能使用别名数据类型。
- length 指定目标数据类型长度的可选整数。默认值为 30。
- style 指定 CONVERT 函数如何转换 expression 的整数表达式。如果样式为 NULL,则返回 NULL。该范围是由 data_type 确定的。有关详细信息,请参阅“备注”部分。
cast() 主要用于数据类型之间的转换,而convert() 则将特定格式(style)的数据类型(expression)转为其他数据类型。
3.4.2. 安全函数¶
对管理安全性有用的函数
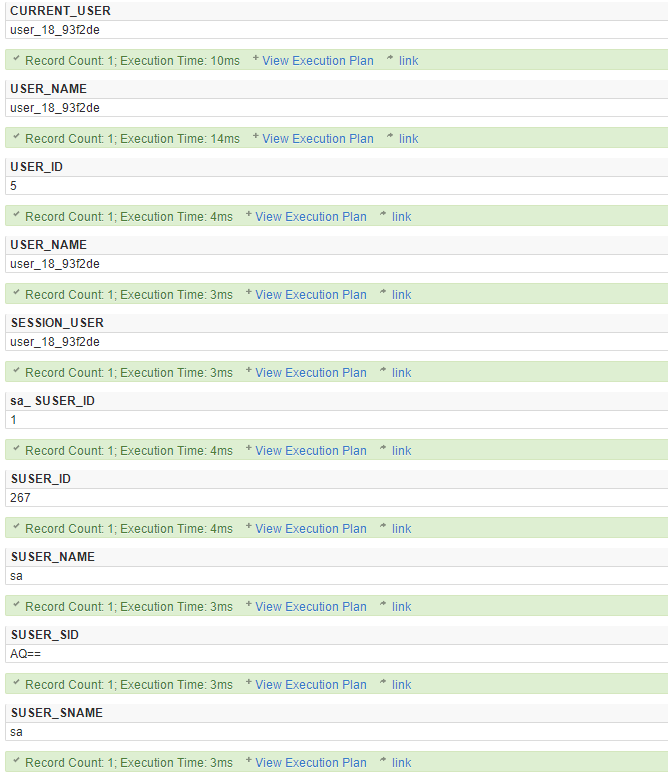
-- 当前用户的名称, 两者等价
SELECT CURRENT_USER;
SELECT USER_NAME();
-- 数据库指定用户的标识号, 用户名缺省则表示当前用户
SELECT USER_ID ( [ 'user' ] );
SELECT USER_ID();
-- 数据库指定标识号的用户名
SELECT USER_NAME([ id ] );
SELECT USER_NAME();
-- 当前数据库中当前上下文的用户名
SELECT SESSION_USER;
-- 用户的登录标识号 SUSER_ID ( [ 'login' ] ) login为登录名
SELECT SUSER_ID('sa');
SELECT SUSER_ID(USER_NAME());
-- 根据用户登录标识号返回用户的登录标识名SUSER_NAME ( [ server_user_id ] )
SELECT SUSER_NAME(1);
-- 指定登录名的安全标识号 (SID)
SELECT SUSER_SID('sa');
-- 与安全标识号 (SID) 关联的登录名
SELECT SUSER_SNAME(0x01);
-- 判断当前账户是否可以访问指定的数据库
SELECT HAS_DBACCESS ('database_name');
-- 判断当前用户是否为指定Microsoft Windows组或SQL Server数据库角色的成员
SELECT IS_MEMBER ( { 'group' | 'role' } );
3.4.3. 元数据函数¶
返回有关数据库和数据库对象的信息
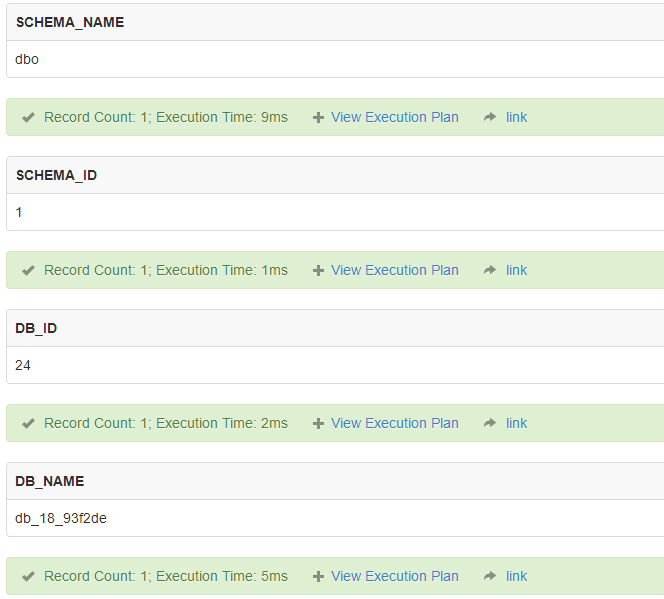
-- 与架构 ID 关联的架构名称 SCHEMA_NAME ([ schema_id ])
SELECT SCHEMA_NAME();
-- 与架构名称关联的架构ID SCHEMA_ID ([ schema_name ])
SELECT SCHEMA_ID();
-- 数据库标识 (ID)号, DB_ID ( [ 'database_name' ] )
SELECT DB_ID();
-- 数据库名称 DB_NAME ( [ database_id ] )
SELECT DB_NAME();
-- 指定表中指定列的定义长度(以字节为单位)
COL_LENGTH ( 'table' , 'column' )
3.4.4. OVER子句(窗口函数)¶
OVER子句确定在应用关联的窗口函数之前,行集的分区和排序。 窗口函数, 也可以被称为OLAP函数或分析函数。
窗口函数是在 ISO SQL 标准中定义的。SQL Server 提供排名开窗函数和聚合开窗函数。窗口是用户指定的一组行。窗口函数计算从窗口派生的结果集中各行的值。
可以在单个查询中将多个排名或聚合窗口函数与单个 FROM 子句一起使用。 窗口函数是整个SQL语句最后被执行的部分,这意味着窗口函数是在SQL查询的结果集上进行的, 因此不会受到Group By, Having,Where子句的影响。
-- 语法
-- 排名函数
Ranking Window Functions
< OVER_CLAUSE > :: =
OVER ( [ PARTITION BY value_expression , ... [ n ] ]
<ORDER BY_Clause>
[ <ROW or RANGE clause> ]
)
-- 聚合函数
Aggregate Window Functions
< OVER_CLAUSE > :: =
OVER ( [ PARTITION BY value_expression , ... [ n ] ]
[ORDER BY order_by_expression ]
[ <ROW or RANGE clause> ]
)
- PARTITION BY 将结果集分为多个分区。开窗函数分别应用于每个分区,并为每个分区重新启动计算。
- value_expression 指定对相应 FROM 子句生成的行集进行分区所依据的列。value_expression 只能引用通过 FROM 子句可用的列。value_expression 不能引用选择列表中的表达式或别名。value_expression 可以是列表达式、标量子查询、标量函数或用户定义的变量。
- <ORDER BY 子句>指定按其执行窗口函数计算的逻辑顺序。
- order_by_expression 指定用于进行排序的列或表达式。 order_by_expression 只能引用可供 FROM 子句使用的列 。 不能将整数指定为表示列名或别名。
- ROWS | RANGE 适用于:SQL Server 2012 (11.x) 及更高版本。 通过指定分区中的起点和终点,进一步限制分区中的行数。 这是通过按照逻辑关联或物理关联对当前行指定某一范围的行实现的。 物理关联通过使用 ROWS 子句实现。
窗口函数(over子句)优势
- 类似Group By的聚合
- 非顺序的访问数据
- 可对窗口函数使用分析函数、聚合函数和排名函数
- 简化了SQL代码(消除Join)
- 消除中间表
窗口函数(over子句)使用场景
- 经典top N问题
比如:找出每个科目排名前N的学生
- 经典排名问题
业务需求“在每组内排名”,比如:每个班级(科目)按成绩来排名
- 在每个组里比较的问题
3.4.5. 聚合函数¶
聚合函数 对一组值执行计算,并返回单个值。 除了COUNT 以外,聚合函数都会 忽略空值 。 聚合函数经常与 SELECT 语句的GROUP BY 子句一起使用。
OVER子句 可以跟在除CHECKSUM 以外的所有聚合函数的后面。
-- AVG ( [ ALL | DISTINCT ] expression ) 平均值
-- MIN ( [ ALL | DISTINCT ] expression ) 最小值
-- MAX ( [ ALL | DISTINCT ] expression ) 最大值
-- SUM ( [ ALL | DISTINCT ] expression ) 和
-- VAR ( [ ALL | DISTINCT ] expression ) 方差
-- VARP ( [ ALL | DISTINCT ] expression ) 总体方差
-- STDEV ( [ ALL | DISTINCT ] expression ) 标准差
-- STDEVP ( [ ALL | DISTINCT ] expression ) 总体标准差
-- COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } ) 项数
-- COUNT_BIG ( { [ ALL | DISTINCT ] expression } | * ) 项数
-- 聚合函数+窗口函数
Aggregate Window Functions
< OVER_CLAUSE > :: =
OVER (
[ PARTITION BY value_expression , ... [ n ] ]
[ORDER BY order_by_expression ]
)
--SQL SERVER 2012 及以上版本
select
s.sid,
sc.cid,
s.sname,
s.ssex,
sc.score,
AVG(sc.score) over(partition BY s.ssex) as [不同性别平均分],
AVG(sc.score) over(partition BY sc.cid) as [不同课程平均分],
SUM(sc.score) over(partition BY sc.sid) as [个人总分],
SUM(sc.score) over(partition BY sc.sid order by sc.cid) as [个人累计总分]
from Student s
left join Score sc
on sc.sid = s.sid
order by s.sid, sc.cid
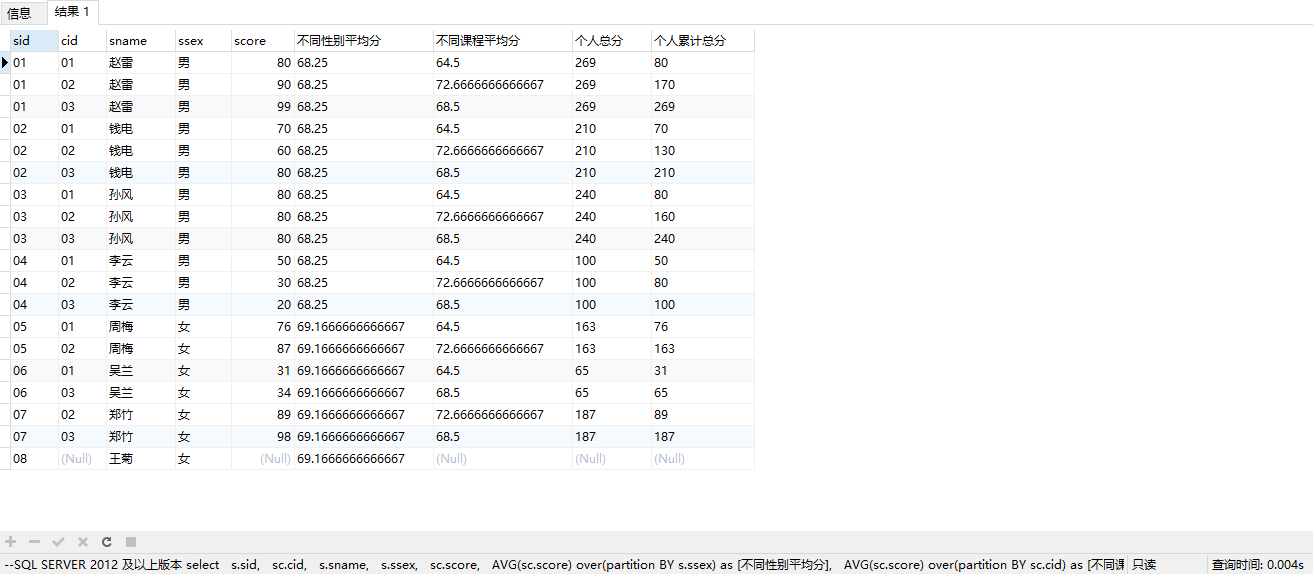
--SQL SERVER 2008 及以前版本
--自连接,利用课程ID来作为累计合计的标志位
with myquery (sid,cid,sname,ssex,score,[不同性别平均分],[不同课程平均分],[个人总分]) as
(select
s.sid,
sc.cid,
s.sname,
s.ssex,
sc.score,
AVG(sc.score) over(partition BY s.ssex) as [不同性别平均分],
AVG(sc.score) over(partition BY sc.cid) as [不同课程平均分],
SUM(sc.score) over(partition BY sc.sid) as [个人总分]
from Student s
left join Score sc
on sc.sid = s.sid
)
select
q1.*,
sum(q2.score) as [个人累计得分]
from myquery as q1
inner join myquery as q2
on q1.sid = q2.sid
and q1.cid >= q2.cid
group by q1.sid,q1.cid,q1.sname,q1.ssex,q1.score,q1.[不同性别平均分],q1.[不同课程平均分],q1.[个人总分]
order by q1.sid, q1.cid
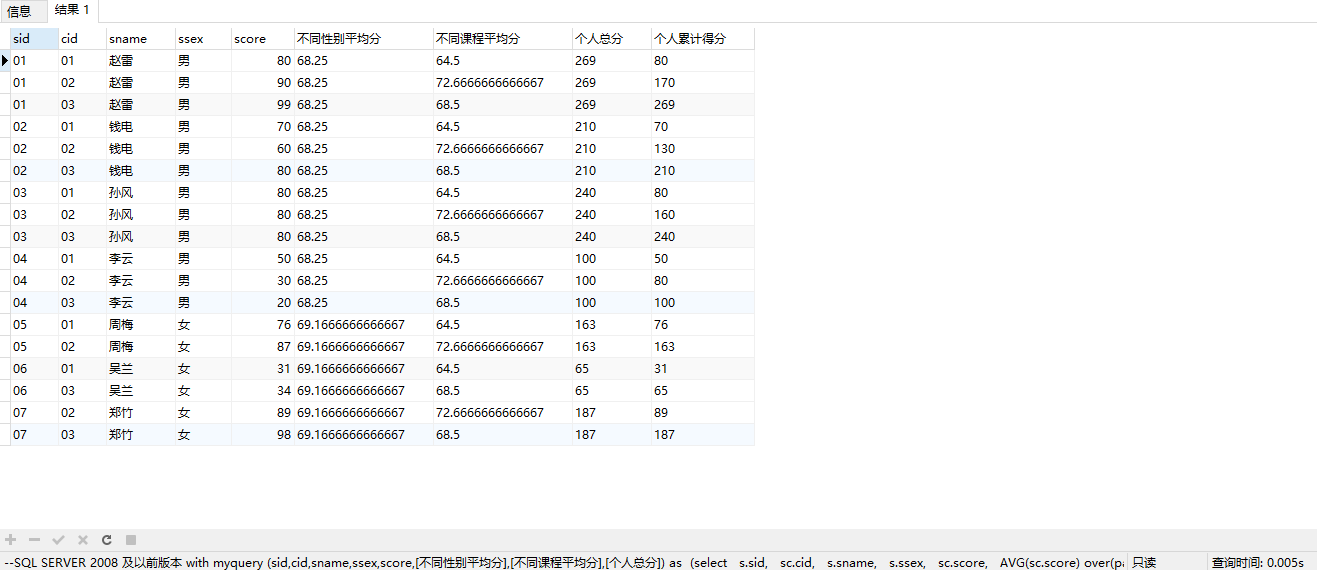
3.4.5.1. GROUPING()¶
指示是否聚合 GROUP BY 列表中的指定列表达式。在结果集中,如果 GROUPING 返回 1 则指示聚合;返回 0 则指示不聚合。如果指定了 GROUP BY,则 GROUPING 只能用在 SELECT 列表、HAVING 和 ORDER BY 子句中。
-- 语法
GROUPING ( <column_expression> )
3.4.5.2. GROUPING_ID()¶
计算分组级别的函数。仅当指定了 GROUP BY时, GROUPING_ID 才能在 SELECT 列表、HAVING 或 ORDER BY 子句中使用。
-- 语法
GROUPING_ID ( <column_expression>[ ,...n ] )
3.4.6. 排名函数¶
排名函数 为分区中的每一行返回一个排名值。根据所用函数的不同,某些行可能与其他行接收到相同的值。排名函数具有不确定性。
-- 排名可能间断(同值同排名)
RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )
-- 排名中没有任何间断 (同值同排名)
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )
-- 将有序分区中的行分发到指定数目(integer_expression)的组中。
NTILE (integer_expression) OVER ( [ <partition_by_clause> ] < order_by_clause > )
-- 结果集分区内行的序列号,每个分区的第一行从 1 开始
ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> )
SELECT p.FirstName, p.LastName
,ROW_NUMBER() OVER (ORDER BY a.PostalCode) AS 'Row Number'
,RANK() OVER (ORDER BY a.PostalCode) AS 'Rank'
,DENSE_RANK() OVER (ORDER BY a.PostalCode) AS 'Dense Rank'
,NTILE(4) OVER (ORDER BY a.PostalCode) AS 'Quartile'
,s.SalesYTD, a.PostalCode
FROM Sales.SalesPerson s
INNER JOIN Person.Person p
ON s.BusinessEntityID = p.BusinessEntityID
INNER JOIN Person.Address a
ON a.AddressID = p.BusinessEntityID
WHERE TerritoryID IS NOT NULL
AND SalesYTD <> 0;
3.4.8. 数学函数¶
算术函数(例如 ABS、CEILING、DEGREES、FLOOR、POWER、RADIANS 和 SIGN)返回与输入值具有相同数据类型的值。三角函数和其他函数(包括 EXP、LOG、LOG10、SQUARE 和 SQRT)将输入值转换为 float 并返回 float 值。
除 RAND 以外的所有 数学函数 都为确定性函数。 这意味着在每次使用特定的输入值集调用这些函数时,它们都将返回相同的结果。仅当指定种子参数时 RAND 才是确定性函数。
--和角度、弧度相关的数学函数
--π的值
SELECT PI();
--RADIANS(numeric_expression) 返回角度值相应的弧度值
SELECT RADIANS(180.0);
--DEGREES(numeric_expression) 返回弧度值相应的角度值
SELECT DEGREES(PI());
--ACOS (float_expression) 反余弦, 取值范围从-1 到 1
SELECT ACOS(0.0);
--ASIN (float_expression) 反正弦, 取值范围从-1 到 1
SELECT ASIN(0.0);
--ATAN (float_expression) 反正切
SELECT ATAN(0.0);
--ATN2 (float_expression,float_expression) 两个向量间的反正切值
SELECT ATN2(0.0, 1.0);
--COS (float_expression) 余弦
SELECT COS(0.0);
--SIN (float_expression) 正弦
SELECT SIN(0.0);
--COT (float_expression) 余切
SELECT COT(1.0);
--TAN (float_expression) 正切
SELECT TAN(PI()/2);
--常用的一些数据函数
--SELECT ABS(numeric_expression) 绝对值
SELECT ABS(-1);
--CEILING (numeric_expression)大于或等于指定数值表达式的最小整数
SELECT CEILING(2.3);
--FLOOR (numeric_expression)小于或等于指定数值表达式的最大整数
SELECT FLOOR(2.3);
--ROUND(numeric_expression , length [ ,function ]) 舍入
--length 必须是 tinyint、smallint 或 int 类型的表达式。如果 length 为正数,则将 numeric_expression 舍入到 length 指定的小数位数。如果 length 为负数,则将 numeric_expression 小数点左边部分舍入到 length 指定的长度。
SELECT ROUND(123.4567,2);
SELECT ROUND(123.4567,-2);
--SIGN(numeric_expression)返回指定表达式的正号 (+1)、零 (0) 或负号 (-1)
SELECT SIGN(2);
SELECT SIGN(0);
SELECT SIGN(-2);
--RAND([ seed ]) 0到1(不包括 0 和 1)之间的伪随机 float 值
SELECT RAND(100);
SELECT RAND();
--和指数、对数、幂指相关的数学函数
--EXP(float_expression) e的指数值
--指数为1,返回e的值
SELECT EXP(1.0);
--LOG(float_expression) 以e为底的对数值
SELECT LOG(2.718);
--LOG10(float_expression) 以10为底的对数值
SELECT LOG10(100);
--POWER(float_expression,y) float_expression的y幂次的值
SELECT POWER(100,0.5);
--SQRT(float_expression) 平方根
SELECT SQRT(100);
--SQUARE(float_expression) 平方
SELECT SQUARE(10);
3.4.9. 字符串函数¶
所有内置字符串函数都是具有确定性的函数。 字符串函数 对字符串输入值执行操作,并返回字符串或数值。
--ASCII(character_expression) 返回最左侧字符的ASCII码值,仅第一个字符
--返回A的ASCII码值65
SELECT ASCII('ABCD');
--UNICODE('ncharacter_expression') 返回unicode字符串中第一个字符的unicode数值
SELECT UNICODE(N'ABCD');
--CHAR(integer_expression) 将ASCII码转换为字符,0至255间整数,否则返回NULL
SELECT CHAR(65);
SELECT CHAR(256);
--CHARINDEX(expression1,expression2[,start_location])
--expression2中搜索expression1 并返回其起始位置(如果找到)。搜索的起始位置为 start_location。
SELECT CHARINDEX('WANG','FIREWANG',1);
--SOUNDEX(character_expression)一个由四个字符组成的代码 (SOUNDEX),用于评估两个字符串的相似性。
SELECT SOUNDEX('WANG');
SELECT SOUNDEX ('FIREWANG');
--DIFFERENCE(character_expression,character_expression)
--两个字符表达式的 SOUNDEX值 的差异。返回的整数是 SOUNDEX 值中相同字符的个数。返回的值从 0 到 4 不等:0 表示几乎不同或完全不同,4 表示几乎相同或完全相同
SELECT DIFFERENCE('WANG','FIREWANG')
--LEFT(character_expression,integer_expression)字符串从左边开始指定个数的字符
SELECT LEFT('FIREWANG',4);
--RIGHT(character_expression,integer_expression)字符串从右边开始指定个数的字符
SELECT RIGHT('FIREWANG',4);
--SUBSTRING (value_expression ,start_expression ,length_expression )
--返回字符表达式、二进制表达式、文本表达式或图像表达式的一部分。
SELECT SUBSTRING('FIREWANG',1,4);
SELECT SUBSTRING('FIREWANG',5,4);
--LEN ( string_expression )字符串长度,不含尾随空格
SELECT LEN('FIRE');
SELECT LEN('FIRE ');
-- LOWER(character_expression) 全部转换为小写字符
SELECT LOWER('FIREWANG');
-- UPPER(character_expression) 全部转换为大写字符
SELECT UPPER('firewang');
--LTRIM(character_expression)删除前导空格
SELECT LTRIM(' FIRE');
--RTRIM(character_expression)删除尾随空格
SELECT RTRIM('FIRE ');
--NCHAR(integer_expression) unicode值对应的unicode字符,0-65535
SELECT NCHAR(100);
SELECT NCHAR(256);
--PATINDEX('%pattern%',expression ) 在字符或者文本数据中搜索指定模式,
--返回指定表达式中某模式第一次出现的起始位置;否则返回0
SELECT PATINDEX('%FIRE%','FIREWANG');
--QUOTENAME ( 'character_string' [ , 'quote_character' ] )
--返回带有分隔符的 Unicode 字符串,分隔符的加入可使输入的字符串成为有效的 SQL Server 分隔标识符。
--用作分隔符的单字符字符串。可以是单引号 (')、左方括号或右方括号 ([], 默认值) 或者英文双引号 (")。
SELECT QUOTENAME('fire[]wang','""');
SELECT QUOTENAME('fire[]wang','''');
SELECT QUOTENAME('fire[]wang','[]');
SELECT QUOTENAME('fire[]wang')
--REPLACE(完整字符串, 要被替换的字符串 , 用于替换的字符串) 替换字符串
SELECT REPLACE('FIREWANG','FIRE','UPUP');
--REPLICATE(string_expression ,integer_expression) 重复指定次数字符串
SELECT REPLICATE('FIREWANG',2);
--REVERSE ( string_expression ) 逆转字符串
SELECT REVERSE('FIREWANG');
--SPACE ( integer_expression ) 返回重复指定次数的空格
SELECT 'FIRE'+SPACE(2)+'WANG';
--STR(float_expression [ , length [ ,decimal ] ])
--将数字数据转换为字符串。
--length 总长度。它包括小数点、符号、数字以及空格。默认值为 10。
--decimal 小数点右边的小数位数。decimal 必须小于等于 16。
SELECT STR(123.456);
SELECT STR(123.456,5);
SELECT STR(123.456,6,1);
--STUFF(character_expression,start,length,character_expression)
--STUFF函数将字符串插入另一字符串。它在第一个字符串中从开始位置start删除指定长度length的字符;然后将第二个字符串插入第一个字符串的开始位置。
SELECT STUFF('FIREWANG',2,3,'1234567'); --F1234567WANG;
3.4.10. 日期和时间函数¶
日期和时间数据类型及函数 的信息和示例
3.4.10.1. 日期和时间数据类型¶
下表列出了 Transact-SQL 的日期和时间数据类型。
| 数据类型 | 格式 | 范围 | 精确度 | 存储大小(字节) | 用户定义的秒的小数精度 | 时区偏移量 |
|---|---|---|---|---|---|---|
| time | hh:mm:ss[.nnnnnnn] | 00:00:00.0000000 到 23:59:59.9999999 | 100 纳秒 | 3 到 5 | Y | N |
| date | YYYY-MM-DD | 0001-01-01 到 9999-12-31 | 1 天 | 3 | N | N |
| smalldatetime | YYYY-MM-DD hh:mm:ss | 1900-01-01 到 2079-06-06 | 1 分钟 | 4 | N | N |
| datetime | YYYY-MM-DD hh:mm:ss[.nnn] | 1753-01-01 到 9999-12-31 | 0.00333 秒 | 8 | N | N |
| datetime2 | YYYY-MM-DD hh:mm:ss[.nnnnnnn] | 0001-01-01 00:00:00.0000000 到 9999-12-31 23:59:59.9999999 | 100 纳秒 | 6 到 8 | Y | N |
| datetimeoffset | YYYY-MM-DD hh:mm:ss[.nnnnnnn] [+|-]hh:mm | 0001-01-01 00:00:00.0000000 到 9999-12-31 23:59:59.9999999(以 UTC 时间表示) | 100 纳秒 | 8 到 10 | Y | Y |
-- 示例各个日期、时间数据类型
SELECT
CAST('2020-02-02 12:13:14.1234567' AS time(7)) AS 'time',
CAST('2020-02-02 12:13:14.1234567' AS date) AS 'date',
CAST('2020-02-02 12:13:14.123' AS smalldatetime) AS 'smalldatetime',
CAST('2020-02-02 12:13:14.123' AS datetime) AS 'datetime',
CAST('2020-02-02 12:13:14.1234567' AS datetime2(7)) AS 'datetime2',
CAST('2020-02-02 12:13:14.1234567' AS datetimeoffset(7)) AS 'datetimeoffset';

3.4.10.2. 系统日期和时间值¶
所有系统日期和时间值均得自运行 SQL Server 实例的计算机的操作系统。
精度较高 的系统日期和时间函数
SQL Server 2008 R2 使用 GetSystemTimeAsFileTime() Windows API 来获取日期和时间值。精确程度取决于运行 SQL Server 实例的计算机硬件和 Windows 版本。此 API 的精度固定为 100 纳秒。可通过使用 GetSystemTimeAdjustment() Windows API 来确定该精确度。
| 函数 | 语法 | 返回值 | 返回数据类型 | 确定性 |
|---|---|---|---|---|
| SYSDATETIME | SYSDATETIME () | 时区偏移量未包含在内。 | datetime2(7) | N |
| SYSDATETIMEOFFSET | SYSDATETIMEOFFSET ( ) | 时区偏移量包含在内。 | datetimeoffset(7) | N |
| SYSUTCDATETIME | SYSUTCDATETIME ( ) | 日期和时间作为 UTC 时间(通用协调时间)返回。 | datetime2(7) | N |
SELECT
SYSDATETIME() AS 'SYSDATETIME',
SYSDATETIMEOFFSET() AS 'SYSDATETIMEOFFSET',
SYSUTCDATETIME() AS 'SYSUTCDATETIME';

精度较低 的系统日期和时间函数
| 函数 | 语法 | 返回值 | 返回数据类型 | 确定性 |
|---|---|---|---|---|
| CURRENT_TIMESTAMP | CURRENT_TIMESTAMP | 返回包含计算机的日期和时间的 datetime2(7) 值,SQL Server 的实例正在该计算机上运行。时区偏移量未包含在内。 | datetime | N |
| GETDATE | GETDATE ( ) | 返回包含计算机的日期和时间的 datetime2(7) 值,SQL Server 的实例正在该计算机上运行。时区偏移量未包含在内。 | datetime | N |
| GETUTCDATE | GETUTCDATE ( ) | 返回包含计算机的日期和时间的 datetime2(7) 值,SQL Server 的实例正在该计算机上运行。日期和时间作为 UTC 时间(通用协调时间)返回。 | datetime | N |
SELECT
CURRENT_TIMESTAMP AS 'CURRENT_TIMESTAMP',
GETDATE() AS 'DATE',
GETUTCDATE() AS 'UTCDATE';

3.4.10.3. 日期和时间部分值¶
| 函数 | 语法 | 返回值 | 返回数据类型 | 确定性 |
|---|---|---|---|---|
| DATENAME | DATENAME ( datepart , date ) | 返回表示指定日期的指定 datepart 的字符串。 | nvarchar | N |
| DATEPART | DATEPART ( datepart , date ) | 返回表示指定 date 的指定 datepart 的整数。 | int | N |
| DAY | DAY ( date ) | 返回表示指定 date 的“日”部分的整数。 | int | Y |
| MONTH | MONTH ( date ) | 返回表示指定 date 的“月”部分的整数。 | int | Y |
| YEAR | YEAR ( date ) | 返回表示指定 date 的“年”部分的整数。 | int | Y |
DATENAME() 和DATEPART() 的 datepart参数完全一样,并且datepart的全写和缩写完全等价,DATENAME()和DATEPART()仅在部分datepart下输出值的不同(当然两种输出值的数据类型是完全不一样的)
| datepart参数 | 缩写 | DATENAME返回值 | DATEPART返回值 |
|---|---|---|---|
| year | yy,yyyy | 2020 | 2020 |
| quarter | qq,q | 1 | 1 |
| month | mm, m | February | 2 |
| dayofyear | dy,y | 33 | 33 |
| day | dd,d | 2 | 2 |
| week | wk,ww | 6 | 6 |
| weekday | dw | Sunday | 1 |
| hour | hh | 12 | 12 |
| minute | mi, n | 13 | 13 |
| second | ss, s | 14 | 14 |
| millisecond | ms | 123 | 123 |
| microsecond | mcs | 123456 | 123456 |
| nanosecond | ns | 123456700 | 123456700 |
| TZoffset | tz | +08:00 | 480 |
| ISO_WEEK | isowk,isoww | 5 | 5 |
SELECT '2020-02-02 12:13:14.1234567';
SELECT
DATENAME(year, '2020-02-02 12:13:14.1234567') as 'year',
DATENAME(quarter, '2020-02-02 12:13:14.1234567') as 'quarter',
DATENAME(month, '2020-02-02 12:13:14.1234567') as 'month',
DATENAME(dayofyear, '2020-02-02 12:13:14.1234567') as 'dayofyear',
DATENAME(day, '2020-02-02 12:13:14.1234567') as 'day',
DATENAME(week, '2020-02-02 12:13:14.1234567') as 'week',
DATENAME(weekday, '2020-02-02 12:13:14.1234567') as 'weekday',
DATENAME(hour, '2020-02-02 12:13:14.1234567') as 'hour',
DATENAME(minute, '2020-02-02 12:13:14.1234567') as 'minute',
DATENAME(second, '2020-02-02 12:13:14.1234567') as 'second',
DATENAME(millisecond, '2020-02-02 12:13:14.1234567') as 'millisecond',
DATENAME(microsecond, '2020-02-02 12:13:14.1234567') as 'mocrosecond',
DATENAME(nanosecond, '2020-02-02 12:13:14.1234567') as 'nanosecond',
--返回偏移量
DATENAME(TZoffset, '2020-02-02 12:13:14.1234567 +8:00') as 'TZoffset',
DATENAME(ISO_WEEK, '2020-02-02 12:13:14.1234567') as 'ISO_WEEK';
SELECT
DATEPART(yy, '2020-02-02 12:13:14.1234567') as 'year',
DATEPART(q, '2020-02-02 12:13:14.1234567') as 'quarter',
DATEPART(mm, '2020-02-02 12:13:14.1234567') as 'month',
DATEPART(dy, '2020-02-02 12:13:14.1234567') as 'dayofyear',
DATEPART(dd, '2020-02-02 12:13:14.1234567') as 'day',
DATEPART(wk, '2020-02-02 12:13:14.1234567') as 'week',
DATEPART(dw, '2020-02-02 12:13:14.1234567') as 'weekday',
DATEPART(hh, '2020-02-02 12:13:14.1234567') as 'hour',
DATEPART(mi, '2020-02-02 12:13:14.1234567') as 'minute',
DATEPART(ss, '2020-02-02 12:13:14.1234567') as 'second',
DATEPART(ms, '2020-02-02 12:13:14.1234567') as 'millisecond',
DATEPART(mcs, '2020-02-02 12:13:14.1234567') as 'mocrosecond',
DATEPART(ns, '2020-02-02 12:13:14.1234567') as 'nanosecond',
--返回偏移的分钟数
DATEPART(tz, '2020-02-02 12:13:14.1234567 +8:00') as 'TZoffset',
DATEPART(isowk, '2020-02-02 12:13:14.1234567') as 'ISO_WEEK';
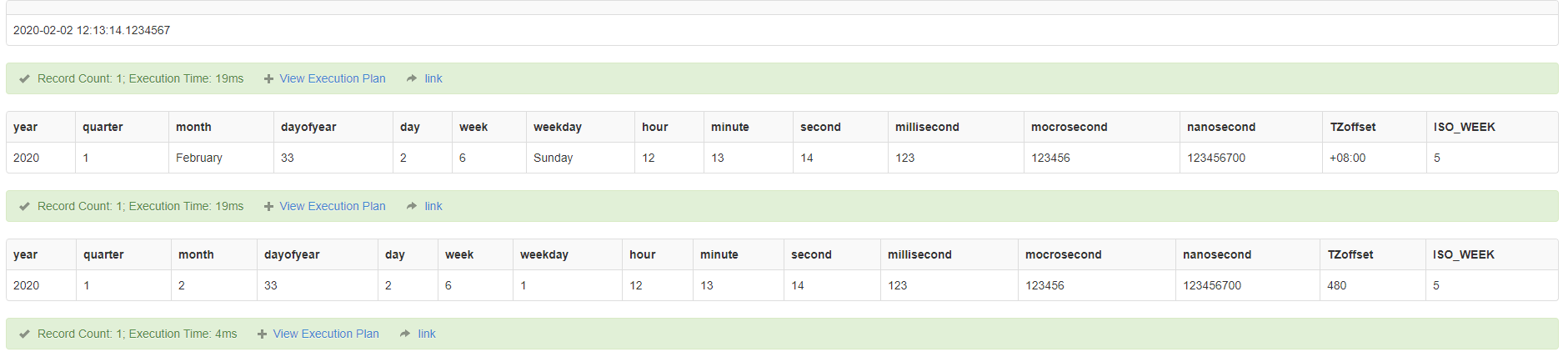
对于DATEPART(),当 datepart 为 week (wk, ww) 或 weekday (dw) 时,返回值取决于使用 SETDATEFIRST 设置的值。
任何年份的 1 月 1 日都用来定义 weekdatepart 的起始数字,例如:DATEPART (wk, ‘Jan 1, xxxx’) = 1,其中 xxxx 为任意年份。
下表列出了针对每个不同的 SET DATEFIRST 参数,“2007-04-21”的 week 和 weekdaydatepart 返回值。1 月 1 日在 2007 年是星期日。4 月 21 日在 2007 年是星期六。SET DATEFIRST 7, Sunday 是美国英语的默认值。
此时相当于星期天被指示为一周的第一天,因此星期六为最后一天,返回值为7。
| SET DATEFIRST参数 | 返回的week | 返回的weekday |
|---|---|---|
| 1 | 16 | 6 |
| 2 | 17 | 5 |
| 3 | 17 | 4 |
| 4 | 17 | 3 |
| 5 | 17 | 2 |
| 6 | 17 | 1 |
| 7 | 16 | 7 |
对于DATEPART() 的 ISO_WEEK ,遵循ISO 8601, 包括 ISO 周-日期系统,即周的编号系统。
每周都与该周内星期四所在的年份关联 。例如,2004 年的第一周 (2004W01) 是指从 2003 年 12 月 29 日(星期一)到 2004 年 1 月 4 日(星期日)。一年中最大的周编号可能是 52 或 53。此样式的编号通常用于欧洲国家/地区,其他地方很少使用。
不同的国家/地区的编号系统可能不符合 ISO 标准。现在至少可能存在六种编号系统,如下表所示:
| 每周的第一天 | 一年的第一周包含 | 分配两次的周 | 使用的国家/地区 |
|---|---|---|---|
| 星期日 | 1 月 1 日,第一个星期六,其中有 1–7 天属于此年 | Y | 美国 |
| 星期一 | 1 月 1 日,第一个星期日,其中有 1–7 天属于此年 | Y | 大多数欧洲国家和英国 |
| 星期一 | 1 月 4 日,第一个星期四,其中有 4-7 天属于此年 | N | ISO 8601,挪威和瑞典 |
| 星期一 | 1 月 7 日,第一个星期一,7 天均属于此年 | N | |
| 星期三 | 1 月 1 日,第一个星期二,其中有 1–7 天属于此年 | Y | |
| 星期六 | 1 月 1 日,第一个星期五,其中有 1–7 天属于此年 | Y |
很容易发现,DAY(), MONTH(), YEAR() 的实现在 DATEPART() 中都已经实现了。
3.4.10.4. 日期和时间差¶
| 函数 | 语法 | 返回值 | 返回数据类型 | 确定性 |
|---|---|---|---|---|
| DATEDIFF | DATEDIFF ( datepart , startdate , enddate ) | 返回两个指定日期之间所跨的日期或时间 datepart 边界的数目。 | int | Y |
datepart参数与 DATEPART() 中除 TZoffset 和 ISO_WEEK 外完全一致,可以认为 DATEDIFF(datepart , startdate , enddate) 就是 DATEPART(datepart , startdate) 与 DATEPART(datepart , enddate) 的差值
3.4.10.5. 修改日期和时间值¶
| 函数 | 语法 | 返回值 | 返回数据类型 | 确定性 |
|---|---|---|---|---|
| DATEADD | DATEADD (datepart , number , date ) | 通过将一个时间间隔与指定 date 的指定 datepart 相加,返回一个新的 datetime 值。 | date 参数的数据类型。 | Y |
| SWITCHOFFSET | SWITCHOFFSET (DATETIMEOFFSET , time_zone) | 更改 DATETIMEOFFSET 值的时区偏移量并保留 UTC 值。 | datetimeoffset 具有的小数精度的DATETIMEOFFSET | Y |
| TODATETIMEOFFSET | TODATETIMEOFFSET (expression , time_zone) | 将 datetime2 值转换为 datetimeoffset 值。datetime2 值被解释为指定 time_zone 的本地时间。 | 具有 datetime 参数的小数精度的 datetimeoffset | Y |
DATEADD() 的datepart参数与 DATEPART() 中除 TZoffset 和 ISO_WEEK 外完全一致。 特别的是, 参数中的 number只能是整数,即int值,如果是浮点数,那么会自动被转换为 int值。
SWITCHOFFSET (DATETIMEOFFSET , time_zone) 中 time_zone 是一个格式为 [+|-]TZH:TZM 的字符串,或是一个表示时区偏移量的带符号的整数(分钟数)。time_zone的范围为 +14 到 -13 ,或者是同样长度的分钟数。
SELECT SWITCHOFFSET('2020-02-02 12:13:14.1234567','+08:00');
SELECT SWITCHOFFSET('2020-02-02 12:13:14.1234567','-08:00');
SELECT SWITCHOFFSET('2020-02-02 12:13:14.1234567',60);
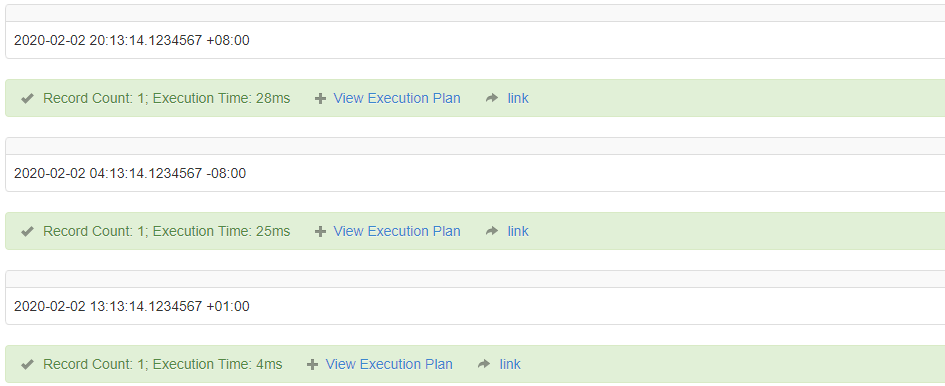
TODATETIMEOFFSET(expression , time_zone) 和 SWITCHOFFSET(DATETIMEOFFSET , time_zone) 用法类似,只不过需要 expression参数为返回值为datetime2数据类型的表达式。
3.4.10.6. 设置或获取会话格式¶
| 函数 | 语法 | 返回值 | 返回数据类型 | 确定性 |
|---|---|---|---|---|
| [@@DATEFIRST](https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms187766(v%3dsql.105)) | @@DATEFIRST | 返回对会话进行 SET DATEFIRST 操作所得结果的当前值。 | tinyint | N |
| SET DATEFIRST | SET DATEFIRST { number | @number_var } | 将一周的第一天设置为从 1 到 7 的一个数字。 | 不适用 | 不适用 |
| SET DATEFORMAT | SET DATEFORMAT { format | @format_var } | 设置用于输入 datetime 或 smalldatetime 数据的日期各部分(月/日/年)的顺序。 | 不适用 | 不适用 |
| [@@LANGUAGE](https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms177557(v%3dsql.105)) | @@LANGUAGE | 返回当前使用的语言的名称。@@LANGUAGE 不是日期或时间函数。但是,语言设置会影响日期函数的输出。 | 不适用 | 不适用 |
| SET LANGUAGE | SET LANGUAGE { [ N ] ‘language’ | @language_var } | 设置会话和系统消息的语言环境。SET LANGUAGE 不是日期或时间函数。但是,语言设置会影响日期函数的输出。 | 不适用 | 不适用 |
| sp_helplanguage | sp_helplanguage [ [ @language = ] ‘language’ ] | 返回有关所有支持语言日期格式的信息。sp_helplanguage 不是日期或时间存储过程。但是,语言设置会影响日期函数的输出。 | 不适用 | 不适用 |
3.4.10.7. 验证日期和时间值¶
| 函数 | 语法 | 返回值 | 返回数据类型 | 确定性 |
|---|---|---|---|---|
| ISDATE | ISDATE ( expression ) | 确定 datetime 或 smalldatetime 输入表达式是否为有效的日期或时间值。 | int , 1或者0 | 只有与 CONVERT 函数一起使用,同时指定了 CONVERT 样式参数且样式不等于 0、100、9 或 109 时,ISDATE 才是确定的。 |
expression: 字符串或者可以转换为字符串表达式。
| ISDATE 表达式 | ISDATE 返回值 |
|---|---|
| date、smalldatetime、datetime | 1 |
| NULL | 0 |
| 除字符串、Unicode 字符串或日期和时间以外的任何数据类型 | 0 |
| text、ntext 或 image 数据类型的值 | 0 |
| 秒精度小数位数超过 3 的任何值(.0000 到 .0000000…n) | 0 |
| 有效日期和无效值混在一起的任何值,例如 1995-10-1a | 0 |
SELECT ISDATE('12:13:14.1234567') AS 'time';
SELECT ISDATE('2020-02-02') AS 'date';
SELECT ISDATE('2020-02-02 12:13:14') AS 'smalldatetime';
SELECT ISDATE('2020-02-02 12:13:14.123') AS 'datetime';
SELECT ISDATE('2020-02-02 12:13:14.1234567') AS 'datetime2';
SELECT ISDATE('2020-02-02 12:13:14.1234567 +8:00') AS 'datetimeoffset';
3.4.10.8. 日期和时间相关主题¶
| 主题 | 说明 |
|---|---|
| 使用日期和时间数据 | 提供通用于日期和时间数据类型及函数的信息和示例(包括日期和时间类型之间的相互转换)。 |
| CAST 和 CONVERT | 提供有关在日期和时间值与字符串文字及其他日期和时间格式之间进行相互转换的信息。 |
| 编写国际化 Transact-SQL 语句 | 提供使用 Transact-SQL 语句的数据库和数据库应用程序在不同语言之间的可移植性准则,或支持多种语言的数据库和数据库应用程序的可移植性准则。 |
| ODBC 标量函数 ) | 提供有关可在 Transact-SQL 语句中使用的 ODBC 标量函数的信息。这包括 ODBC 日期和时间函数。 |
| 分布式查询的数据类型映射 | 提供有关以下方面的信息:日期和时间数据类型对具有不同版本的 SQL Server 或不同访问接口的服务器之间的分布式查询有何影响。 |
利用cast()和convert() 转换日期和时间数据类型。
-- CAST()语法,数据类型之间相互转换:
CAST ( expression AS data_type [ ( length ) ] )
-- CONVERT()语法, 将指定style的数据类型值转化为另一数据类型:
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
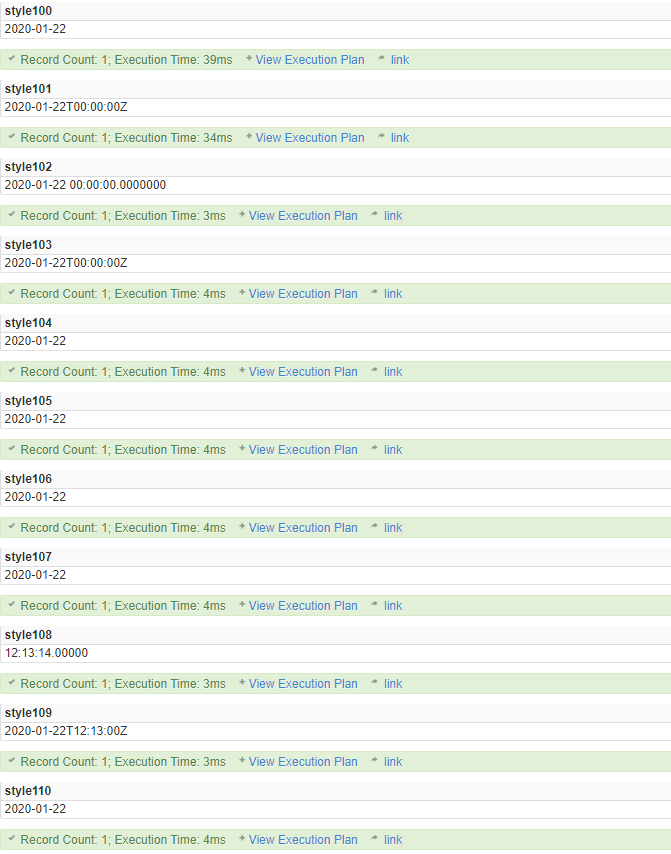
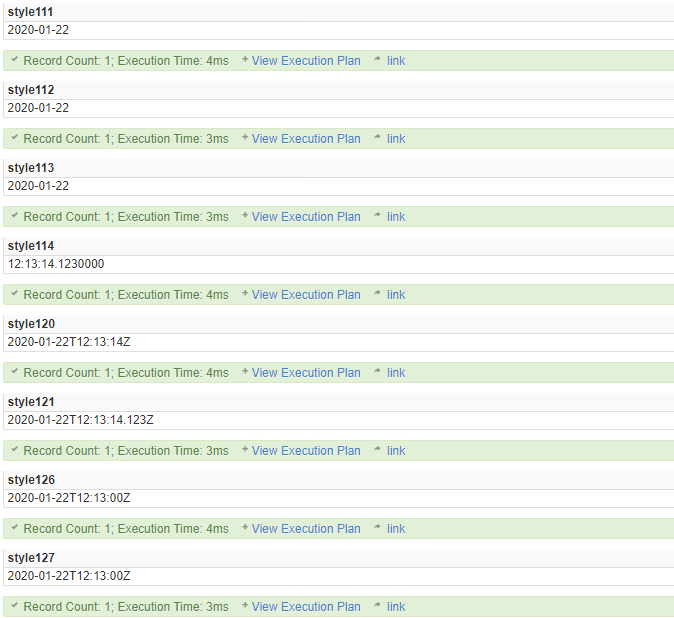
如果 expression 为 date 或 time 数据类型,则 style 可以为下表中显示的值之一。其他值作为 0 进行处理。SQL Server 使用科威特算法来支持阿拉伯样式(回历)的日期格式。
| 不带世纪数位 (yy) (1) | 带世纪数位 (yyyy) | 标准 | 输入/输出 (3) |
|---|---|---|---|
| 0 或 100 (1,2) | 默认 | mon dd yyyy hh:miAM(或 PM) | |
| 1 | 101 | 美国 | mm/dd/yyyy |
| 2 | 102 | ANSI | yy.mm.dd |
| 3 | 103 | 英国/法国 | dd/mm/yyyy |
| 4 | 104 | 德国 | dd.mm.yy |
| 5 | 105 | 意大利 | dd-mm-yy |
| 6 | 106(1) | dd mon yy | |
| 7 | 107(1) | mon dd, yy | |
| 8 | 108 | hh:mi:ss | |
| 9 或 109(1、2) | 默认设置 + 毫秒 | mon dd yyyy hh:mi:ss:mmmAM(或 PM) | |
| 10 | 110 | 美国 | mm-dd-yy |
| 11 | 111 | 日本 | yy/mm/dd |
| 12 | 112 | ISO | yymmdd yyyymmdd |
| 13 或 113 (1,2) | 欧洲默认设置 + 毫秒 | dd mon yyyy hh:mi:ss:mmm(24h) | |
| 14 | 114 | hh:mi:ss:mmm(24h) | |
| 20 或 120 (2) | ODBC 规范 | yyyy-mm-dd hh:mi:ss(24h) | |
| 21 或 121 (2) | ODBC 规范(带毫秒) | yyyy-mm-dd hh:mi:ss.mmm(24h) | |
| 126 (4) | ISO8601 | yyyy-mm-ddThh:mi:ss.mmm(无空格) | |
| 127(6, 7) | 带时区 Z 的 ISO8601。 | yyyy-mm-ddThh:mi:ss.mmmZ(无空格) | |
| 130 (1,2) | 回历 (5) | dd mon yyyy hh:mi:ss:mmmAM | |
| 131 (2) | 回历 (5) | dd/mm/yy hh:mi:ss:mmmAM |
--style指定的是源数据的格式
--新数据的格式由数据类型来决定
SELECT CONVERT(date, 'Jan 22 2020 12:13:14', 100);
SELECT CONVERT(datetime, '01/22/2020', 101);
SELECT CONVERT(datetime2, '2020.01.22', 102);
SELECT CONVERT(smalldatetime, '22/01/2020', 103);
SELECT CONVERT(date, '22/01/2020', 104);
SELECT CONVERT(date, '22-01-2020', 105);
SELECT CONVERT(date, '22 Jan 2020', 106);
SELECT CONVERT(date, 'Jan 22,2020', 107);
SELECT CONVERT(time(5), '12:13:14', 108);
SELECT CONVERT(smalldatetime, 'Jan 22 2020 12:13:14.123', 109);
SELECT CONVERT(date, '01-22-2020', 110);
SELECT CONVERT(date, '2020/01/22', 111);
SELECT CONVERT(date, '20200122', 112);
SELECT CONVERT(date, '22 Jan 2020 12:13:14.123', 113);
SELECT CONVERT(time(7), '12:13:14.123', 114);
SELECT CONVERT(datetime, '2020-01-22 12:13:14', 120);
SELECT CONVERT(datetime, '2020-01-22 12:13:14.123', 121);
SELECT CONVERT(smalldatetime, '2020-01-22T12:13:14.123', 126);
SELECT CONVERT(smalldatetime, '2020-01-22T12:13:14.123', 127);
3.5. Transact-SQL 表达式¶
表达式是标识符、值和运算符的组合,SQL Server 可以对其求值以获取结果。访问或更改数据时,可在多个不同的位置使用数据。例如,可以将表达式用作要在查询中检索的数据的一部分,也可以用作查找满足一组条件的数据时的搜索条件。
表达式可以是下列任何一种:
- 常量
- 函数
- 列名
- 变量
- 子查询
- CASE、NULLIF 或 COALESCE
还可以用运算符对这些实体进行组合以生成表达式。
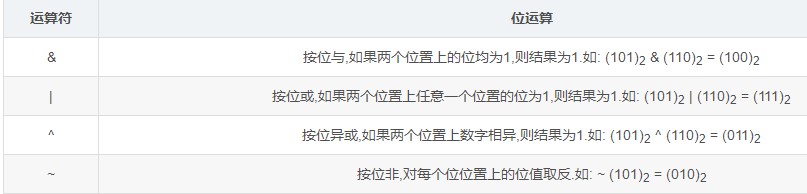
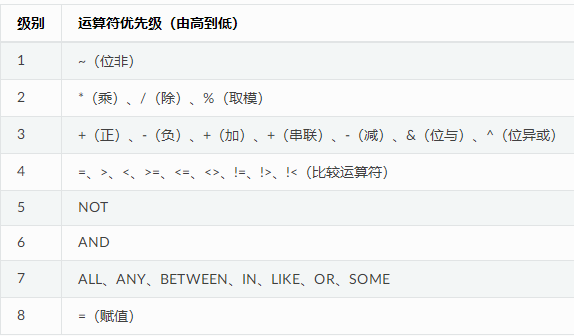
3.6. Transact-SQL 运算符¶
| 算术运算符 | 含义 |
|---|---|
| +(加) | 加,也可以将一个以天为单位的数字加到日期中 |
| -(减) | 减,也可以从日期中减去一个以天为单位的数字 |
| *(乘) | 乘 |
| / (Divide) | 除 |
| %(取模) | 返回一个除法运算的整数余数. |
| 逻辑运算符 | 含义 |
|---|---|
| ALL | 如果一组的比较都为TRUE,那么就为TRUE. |
| AND | 如果两个布尔表达式都为TRUE,那么就为TRUE. |
| ANY | 如果一组的比较中任何一个为TRUE,那么就为TRUE. |
| BETWEEN | 如果操作数在某个范围之内,那么就为TRUE. |
| EXISTS | 如果子查询包含一些行,那么就为TRUE. |
| IN | 如果操作数等于表达式列表中的一个,那么就为TRUE. |
| LIKE | 如果操作数与一种模式相匹配,那么就为TRUE. |
| NOT | 对任何其他布尔运算符的值取反. |
| OR | 如果两个布尔表达式中的一个为TRUE,那么就为TRUE. |
| SOME | 如果在一组比较中,有些为TRUE,那么就为 TRUE. |
| 比较运算符 | 含义 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| > | 大于 |
| >= | 大于或等于 |
| < | 小于 |
| <= | 小于或等于 |
| != | 不等于 |
| !< | 不小于 |
| !> | 不大于 |
3.7. Transact-SQL 注释¶
注释是程序代码中不执行的文本字符串(也称为备注)。注释可用于对代码进行说明或暂时禁用正在进行诊断的部分 Transact-SQL 语句和批。使用注释对代码进行说明,便于将来对程序代码进行维护。
SQL Server 支持两种类型的注释字符:
- –(双连字符)。这些注释字符可与要执行的代码处在同一行,也可另起一行。从双连字符开始到行尾的内容均为注释。对于多行注释,必须在每个注释行的前面使用双连字符。
- \(/* ... */\) (正斜杠-星号字符对)。这些注释字符可与要执行的代码处在同一行,也可另起一行,甚至可以在可执行代码内部。
3.8. Transact-SQL 保留关键字¶
Microsoft SQL Server 将保留关键字用于定义、操作和访问数据库。保留关键字是 SQL Server 使用的 Transact-SQL 语言语法的一部分,用于分析和理解 Transact-SQL 语句和批处理。尽管在 Transact-SQL 脚本中使用 SQL Server 保留关键字作为标识符和对象名在语法上是可行的,但规定只能使用分隔标识符。
下表列出了 SQL Server 保留关键字。
| 关键字 | 关键字 | 关键字 |
|---|---|---|
| ADD | EXISTS | PRECISION |
| ALL | EXIT | PRIMARY |
| ALTER | EXTERNAL | |
| AND | FETCH | PROC |
| ANY | FILE | PROCEDURE |
| AS | FILLFACTOR | PUBLIC |
| ASC | FOR | RAISERROR |
| AUTHORIZATION | FOREIGN | READ |
| BACKUP | FREETEXT | READTEXT |
| BEGIN | FREETEXTTABLE | RECONFIGURE |
| BETWEEN | FROM | REFERENCES |
| BREAK | FULL | REPLICATION |
| BROWSE | FUNCTION | RESTORE |
| BULK | GOTO | RESTRICT |
| BY | GRANT | RETURN |
| CASCADE | GROUP | REVERT |
| CASE | HAVING | REVOKE |
| CHECK | HOLDLOCK | RIGHT |
| CHECKPOINT | IDENTITY | ROLLBACK |
| CLOSE | IDENTITY_INSERT | ROWCOUNT |
| CLUSTERED | IDENTITYCOL | ROWGUIDCOL |
| COALESCE | IF | RULE |
| COLLATE | IN | SAVE |
| COLUMN | INDEX | SCHEMA |
| COMMIT | INNER | SECURITYAUDIT |
| COMPUTE | INSERT | SELECT |
| CONSTRAINT | INTERSECT | SESSION_USER |
| CONTAINS | INTO | SET |
| CONTAINSTABLE | IS | SETUSER |
| CONTINUE | JOIN | SHUTDOWN |
| CONVERT | KEY | SOME |
| CREATE | KILL | STATISTICS |
| CROSS | LEFT | SYSTEM_USER |
| CURRENT | LIKE | TABLE |
| CURRENT_DATE | LINENO | TABLESAMPLE |
| CURRENT_TIME | LOAD | TEXTSIZE |
| CURRENT_TIMESTAMP | MERGE | THEN |
| CURRENT_USER | NATIONAL | TO |
| CURSOR | NOCHECK | TOP |
| DATABASE | NONCLUSTERED | TRAN |
| DBCC | NOT | TRANSACTION |
| DEALLOCATE | NULL | TRIGGER |
| DECLARE | NULLIF | TRUNCATE |
| DEFAULT | OF | TSEQUAL |
| DELETE | OFF | UNION |
| DENY | OFFSETS | UNIQUE |
| DESC | ON | UNPIVOT |
| DISK | OPEN | UPDATE |
| DISTINCT | OPENDATASOURCE | UPDATETEXT |
| DISTRIBUTED | OPENQUERY | USE |
| DOUBLE | OPENROWSET | USER |
| DROP | OPENXML | VALUES |
| DUMP | OPTION | VARYING |
| ELSE | OR | VIEW |
| END | ORDER | WAITFOR |
| ERRLVL | OUTER | WHEN |
| ESCAPE | OVER | WHERE |
| EXCEPT | PERCENT | WHILE |
| EXEC | PIVOT | WITH |
| EXECUTE | PLAN | WRITETEXT |
3.9. Transact-SQL 语法约定¶
| 约定 | 使用场景 |
|---|---|
| 大写 | Transact-SQL 关键字。 |
| 斜体 | 用户提供的 Transact-SQL 语法的参数。 |
| 粗体 | 数据库名、表名、列名、索引名、存储过程、实用工具、数据类型名以及必须按所显示的原样键入的文本。 |
| 下划线 | 指示当语句中省略了包含带下划线的值的子句时应用的默认值。 |
| |(竖线) | 分隔括号或大括号中的语法项。只能使用其中一项。 |
| [ ](方括号) | 可选语法项。不要键入方括号。 |
| { }(大括号) | 必选语法项。不要键入大括号。 |
| [,…n] | 指示前面的项可以重复 n 次。各项之间以逗号分隔。 |
| […n] | 指示前面的项可以重复 n 次。每一项由空格分隔。 |
| ; | Transact-SQL 语句终止符。 |
| ::= | 语法块的名称。此约定用于对可在语句中的多个位置使用的过长语法段或语法单元进行分组和标记。可使用语法块的每个位置由括在尖括号内的标签指示:。集是表达式的集合,例如 ;列表是集的集合,例如 。 |
除非另外指定,否则,所有对数据库对象名的 Transact-SQL 引用将是由四部分组成的名称,格式如下:
server_name.[database_name]**.**[schema_name]**.**object_name
database_name.[schema_name]**.**object_name
schema_name.object_name
object_name
- server_name 指定链接的服务器名称或远程服务器名称。
- database_name 如果对象驻留在 SQL Server 的本地实例中,则指定 SQL Server 数据库的名称。如果对象在链接服务器中,则 database_name 将指定 OLE DB 目录。
- schema_name 如果对象在 SQL Server 数据库中,则指定包含对象的架构的名称。如果对象在链接服务器中,则 schema_name 将指定 OLE DB 架构名称。
- object_name 对象的名称。