4. Select查询¶
4.1. 查询基础知识¶
查询是对存储在 SQL Server 中的数据的一种请求。可以使用下列几种形式发出查询:
- MS Query 或 Microsoft Access 用户可使用图形用户界面 (GUI) 从一个或多个 SQL Server 表中选择想要查看的数据。
- 使用 SQL Server Management Studio 或 osql 实用工具的用户可发出 SELECT 语句。
- 客户端或基于中间层的应用程序(如 Microsoft Visual Basic 应用程序)可将 SQL Server 表中的数据映射到绑定控件(如网格)。
尽管查询使用多种方式与用户交互,但它们都完成相同的任务:它们为用户提供 SELECT 语句的结果集。即使用户从不指定 SELECT 语句,与使用图形化工具(如 Visual Studio Query Designer)所经常遇到的情况一样,客户端软件可将每个用户查询转换成发送到 SQL Server 的 SELECT 语句。
SELECT 语句从 SQL Server 中检索出数据,然后以一个或多个结果集的形式将其返回给用户。结果集是对来自 SELECT 语句的数据的表格排列。与 SQL 表相同,结果集由行和列组成。
大多数 SELECT 语句都描述结果集的四个主要属性:
- 结果集中的列的数量和属性。对于每个结果集列来说,必须定义下列属性:
- 列的数据类型。
- 列的大小以及数值列的精度和小数位数。
- 返回到列中的数据值的源。
- 从中检索结果集数据的表,以及这些表之间的所有逻辑关系。(From)
- 为了符合 SELECT 语句的要求,源表中的行所必须达到的条件。不符合条件的行会被忽略。(Where)
- 结果集的行的排列顺序。(Order by)
例如下列 SELECT 语句查找单价超过 $40 的产品的产品 ID、名称以及标价
SELECT ProductID, Name, ListPrice
FROM Production.Product
WHERE ListPrice > $40
ORDER BY ListPrice ASC
在 SELECT 关键字之后所列出的列名(ProductID、Name 和 ListPrice)形成选择列表。此列表指定结果集有三列,并且每一列都具有 Product 表中相关列的名称、数据类型和大小。因为 FROM 子句仅指定了一个基表,所以 SELECT 语句中的所有列名都引用该表中的列。
FROM 子句仅列出 Product 这一个表,该表用来检索数据。
WHERE 子句指定出条件:在 Product 表中,只有 ListPrice 列中的值大于 $40,该值所在的行才符合 SELECT 语句的要求。
ORDER BY 子句指定结果集将基于 ListPrice 列中的值按照升序进行排序 (ASC)。
4.2. SELECT语句组成¶
Select的主要子句可归纳如下:
SELECT
[ ALL | DISTINCT ]
[TOP (expression) [PERCENT] [ WITH TIES ] ]
select_list
INTO new_table_name
FROM table_list
[ WHERE search_conditions ]
[ GROUP BY group_by_list ]
[ HAVING search_conditions ]
[ ORDER BY order_list [ ASC | DESC ] ]
select_list 描述结果集的列。它是一个逗号分隔的表达式列表。每个表达式同时定义格式(数据类型和大小)和结果集列的数据来源。通常,每个选择列表表达式都是对数据所在的源表或视图中的列的引用,但也可能是对任何其他表达式(例如,常量或 Transact-SQL 函数)的引用。在选择列表中使用 ***** 表达式可指定返回源表的所有列。
INTO new_table_name 指定使用结果集来创建新表。new_table_name 指定新表的名称。
FROM table_list 包含从中检索到结果集数据的表的列表。这些来源可以是:
- 运行 SQL Server 的本地服务器中的基表。
- 本地 SQL Server 实例中的视图。SQL Server 在内部将一个视图引用按照组成该视图的基表解析为多个引用。
- 链接表。它们是 OLE DB 数据源中的表,称之为“分布式查询”。通过将 OLE DB 数据源链接为链接服务器,或在 OPENROWSET 或 OPENQUERY 函数中引用数据源,可以从 SQL Server 访问 OLE DB 数据源。
FROM 子句还可以包含联接规范。这些联接规范定义了 SQL Server 在从一个表导航到另一个表时使用的特定路径。
FROM 子句还用在 DELETE 和 UPDATE 语句中以定义要修改的表。
WHERE search_conditions WHERE 子句是一个筛选,只有符合条件的行才向结果集提供数据。
WHERE 子句还用在 DELETE 和 UPDATE 语句中以定义目标表中要修改的行。
GROUP BY group_by_list GROUP BY 子句根据 group_by_list 列中的值将结果集分成组。
HAVING search_conditions HAVING 子句是应用于结果集的附加筛选。从逻辑上讲,HAVING 子句是从应用了任何 FROM、WHERE 或 GROUP BY 子句的 SELECT 语句而生成的中间结果集中筛选行。尽管 HAVING 子句前并不是必须要有 GROUP BY 子句,但 HAVING 子句通常与 GROUP BY 子句一起使用。
ORDER BY order_list[ ASC | DESC ] ORDER BY 子句定义了结果集中行的排序顺序。order_list 指定组成排序列表的结果集列。关键字 ASC 和 DESC 用于指定排序行的排列顺序是升序还是降序。
ORDER BY 之所以重要,是因为关系理论规定除非已经指定 ORDER BY,否则不能假设结果集中的行带有任何序列。如果结果集行的顺序对于 SELECT 语句来说很重要,那么在该语句中就必须使用 ORDER BY 子句。
4.3. SELECT 语句的逻辑处理顺序¶
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- WITH CUBE 或 WITH ROLLUP
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP
4.4. 选择列表¶
结果集列的以下特性由选择列表中的下列表达式定义:
- 结果集列与定义该列的表达式的数据类型、大小、精度以及小数位数相同。
- 结果集列的名称与定义该列的表达式的名称相关联。可选的 AS 关键字可用于更改名称,或者在表达式没有名称时为其分配名称。这样做可以增加可读性。
- 结果集列的数据值通过对结果集的每一行相应的表达式求值而得出。
选择列表还可以包含下列控制结果集最终格式的关键字:
-
- DISTINCT 关键字可从 SELECT 语句的结果中消除重复的行。如果没有指定 DISTINCT,将返回所有行,包括重复的行。
- 空值将被认为是相互重复的内容。不论遇到多少个空值,结果中只返回一个 NULL。
-
- TOP ( expression ) [ PERCENT ] [ WITH TIES ] ; expression 是指定返回行数的数值表达式,如果指定了 PERCENT,则是指返回的结果集行的百分比(由 expression 指定)
TOP (120) /*返回120行*/ TOP (15) PERCENT /* 返回前15%的行结果 */. TOP(@n) /* 返回变量n指定数量的行结果,比如:DECLARE @n AS BIGINT; SET @n = 2 */.
选择列表中的项包括下列内容:
一个简单表达式,例如:对函数、变量、常量或者表或视图中的列的引用。
一个标量子查询。该 SELECT 语句将每个结果集行计算为单个值。
一个复杂表达式,通过对一个或多个简单表达式使用运算符而生成。这使结果集中得以包含基表中不存在,但是根据基表中存储的值计算得到的值。这些结果集列被称为派生列。
表达式可以包含 $ROWGUID 关键字。它解析为对表中具有 ROWGUIDCOL 属性的列的引用。
对数值列或常量使用算术运算符或函数进行的计算和运算
SELECT ProductID, ROUND( (ListPrice * .9), 2) AS DiscountPrice FROM Production.Product WHERE ProductID = 748;
数据类型转换(cast)
SELECT ( CAST(ProductID AS VARCHAR(10)) + ': ' + Name ) AS ProductIDName FROM Production.Product;
CASE 表达式
SELECT ProductID, Name, CASE Class WHEN 'H' THEN ROUND( (ListPrice * .6), 2) WHEN 'L' THEN ROUND( (ListPrice * .7), 2) WHEN 'M' THEN ROUND( (ListPrice * .8), 2) ELSE ROUND( (ListPrice * .9), 2) END AS DiscountPrice FROM Production.Product;
子查询
SELECT Prd.ProductID, Prd.Name, ( SELECT SUM(OD.UnitPrice * OD.OrderQty) FROM AdventureWorks2008R2.Sales.SalesOrderDetail AS OD WHERE OD.ProductID = Prd.ProductID ) AS SumOfSales FROM Production.Product AS Prd ORDER BY Prd.ProductID;
* 符号。如果没有使用限定符指定,星号 (*) 将被解析为对 FROM 子句中指定的所有表或视图中的所有列的引用。
变量赋值的格式为:*@*local_variable = 表达式。SET *@*local_variable 语句也可用于变量赋值。
4.5. FROM子句¶
在每一个要从表或视图中检索数据的 SELCET 语句中,都需要使用 FROM 子句。使用 FROM 子句可以:
- 列出选择列表和 WHERE 子句中所引用的列所在的表和视图。可以使用 AS 子句为表和视图的名称指定别名。
- 联接类型。这些类型由 ON 子句中指定的联接条件限定。
FROM 子句是用逗号分隔的表名、视图名和 JOIN 子句的列表。
Transact-SQL 具有扩展功能,支持在 FROM 子句中指定除表或视图之外的其他对象。这些对象返回结果集,也就是 OLE DB 术语中所说的行集,该结果集构成了虚拟表。然后 SELECT 语句就像操作表一样操作这些结果集。
FROM 子句可以指定
一个或多个表或视图
两个或多个表或视图之间的联接(join)
一个或多个派生表,这些派生表是 FROM 子句中的 SELECT 语句,由别名或用户指定的名称引用。FROM 子句中 SELECT 语句的结果集构成了外层 SELECT 语句所用的表。
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Name, d.City FROM Person.Person AS p INNER JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID INNER JOIN Person.BusinessEntityAddress AS bea ON e.BusinessEntityID = bea.BusinessEntityID INNER JOIN (SELECT AddressID, City FROM Person.Address) AS d ON bea.AddressID = d.AddressID ORDER BY p.LastName, p.FirstName ;
使用 APPLY 运算符根据左侧输入表中的每一行计算右侧的输入(通常是表值函数),并将所有这些计算的结果合并起来。(数据库兼容级别必须至少为 90)
使用 PIVOT 和 UNPIVOT 运算符来改造输入表。PIVOT 通过将表达式某一列中的唯一值转换为输出中的多个列来旋转表值表达式,并在必要时对最终输出中所需的任何其余列值执行聚合。UNPIVOT 与 PIVOT 执行相反的操作,将表值表达式的列转换为列值。(数据库的兼容级别需要90以上 )
用 sp_addlinkedserver 定义的链接服务器中的一个或多个表或视图。链接服务器可以是任何 OLE DB 数据源。
OPENROWSET 或 OPENQUERY 函数返回的 OLE DB 行集。
不需要 FROM 子句的 SELECT 语句是那些不从数据库内的任何表中选择数据的 SELECT 语句。这些 SELECT 语句只从局部变量或不对列进行操作的 Transact-SQL 函数中选择数据:
SELECT SYSDATETIME();
SELECT @MyIntVariable;
SELECT @@VERSION;
4.6. PIVOT和UNPIVOT¶
PIVOT 通过将表达式中的一个列的唯一值转换为输出中的多列(即行转列),来轮替表值表达式。 PIVOT 在需要对最终输出所需的所有剩余列值执行聚合时运行聚合。 与 PIVOT 执行的操作相反,UNPIVOT 将表值表达式的列轮换为行(即列转行)。
但是需要注意得是,UNPIVOT 并不完全是 PIVOT 的逆操作。PIVOT 执行聚合,并将多个可能的行合并为输出中的一行。 UNPIVOT 不重现原始表值表达式的结果,因为行已被合并。
-- PIVOT 语法
SELECT <非透视的列>,
[第一个透视的列] AS <列名称>,
[第二个透视的列] AS <列名称>,
...
[最后一个透视的列] AS <列名称>,
FROM
(<生成数据的 SELECT 查询>)
AS <源查询的别名>
PIVOT
(
<聚合函数>(<要聚合的列>)
FOR
[<包含要成为列标题的值的列>]
IN ( [第一个透视的列], [第二个透视的列],
... [最后一个透视的列])
) AS <透视表的别名>
<可选的 ORDER BY 子句>;
SELECT VendorID, [250] AS Emp1, [251] AS Emp2, [256] AS Emp3, [257] AS Emp4
FROM
(SELECT PurchaseOrderID, EmployeeID, VendorID
FROM Purchasing.PurchaseOrderHeader) p
PIVOT
(
COUNT (PurchaseOrderID)
FOR EmployeeID IN
( [250], [251], [256], [257] )
) AS pvt
ORDER BY pvt.VendorID;
/* pivot result
VendorID Emp1 Emp2 Emp3 Emp4
1492 2 5 4 4
1494 2 5 4 5
1496 2 4 4 5
1498 2 5 4 4
1500 3 4 4 5
*/
-- 查看每个人的年龄,性别,三门课成绩
select
sid,sname,sage,ssex,[语文],[数学],[英语]
from
(
select a.sid,a.sname,a.sage,a.ssex,c.cname,b.score
from Student a
left join Score b
on a.sid=b.sid
left join Course c
on b.cid = c.cid
) source_table
pivot(
sum(score) for
cname in (
[语文],[数学],[英语]
)
) t
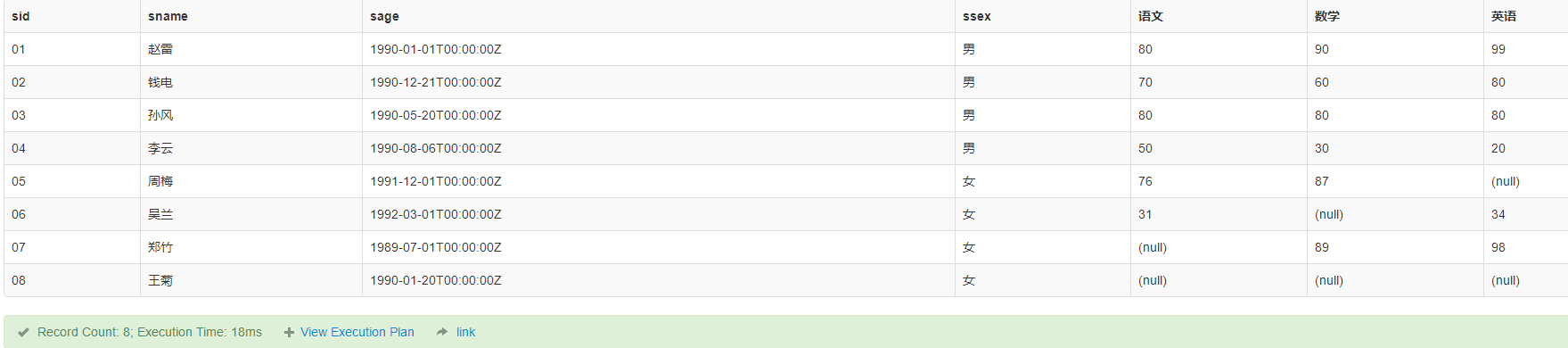 student_pivot
student_pivot
将上述结果新建表 Student_pivot
-- unpivot 语法
SELECT [columns not unpivoted],
[unpivot_column],
[value_column],
FROM
(<source query>)
AS <alias for the source data>
UNPIVOT ( [value_column] FOR [unpivot_column] IN ( <column_list> ) )
AS <alias for unpivot>
Where:
--[columns not unpivoted]: 没有被转换的列名。
--[unpivot_column]: 转换的各列所汇总到的单列的名称。
--[value_column]: 转换的各列数据所汇总到的单列的名称。
--<source query>: 源数据。
--<alias for the source data>: 为源数据转换后的表确定一个别名。
--<column_list>: 被转换的列的各列的名称。
--<alias for unpivot>: 转换操作的整个过程的别名。
select
sid,
sname,
sage,
ssex,
subject,
score
from
(select * from Student_pivot) as sp
UNPIVOT(
score for subject in ([语文],[数学],[英语])
) as t
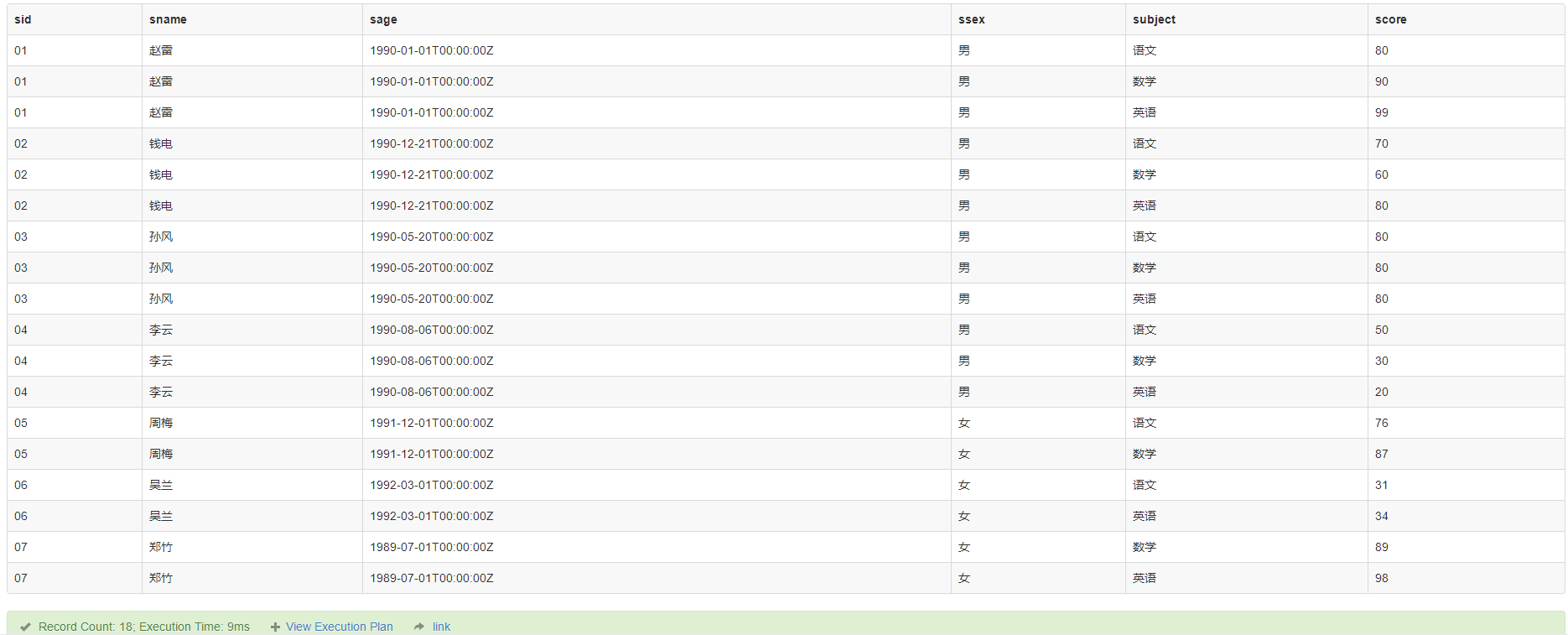 unpivot
unpivot
特别注意那些成绩为空的行记录都没有出现!
4.7. WHERE和HAVING筛选结果¶
SELECT 语句中的 WHERE 和 HAVING 子句可以控制用于生成结果集的源表中的行。WHERE 和 HAVING 是筛选器。这两个子句指定一系列搜索条件,只有那些满足搜索条件的行才用于生成结果集。我们称满足搜索条件的行包含在结果集中。
HAVING 子句通常与 GROUP BY 子句一起使用来筛选聚合值的结果。但是,也可以不使用 GROUP BY 而单独指定 HAVING。HAVING 子句指定在 WHERE 子句筛选之后应用的其他筛选器。这些筛选器可应用于选择列表中使用的聚合函数。
理解应用 WHERE、GROUP BY 和 HAVING 子句的正确顺序对编写高效的查询代码会有所帮助:
- WHERE 子句用来筛选 FROM 子句中指定的操作所产生的行。
- GROUP BY 子句用来分组 WHERE 子句的输出。
- HAVING 子句用来从分组的结果中筛选行。
WHERE 和 HAVING 子句中的搜索条件或限定条件可以包括:
比较运算符,例如:=、< >、< 和 >
SELECT ProductID, Name FROM Production.Product WHERE Class = 'H' ORDER BY ProductID;
范围(BETWEEN 和 NOT BETWEEN)
-- 100到500之间 SELECT ProductID, Name FROM Production.Product WHERE ListPrice BETWEEN 100 and 500 ORDER BY ListPrice;
列表(IN 和 NOT IN)
-- 如果不适用IN,就需要用多个or -- 使用IN更简洁 SELECT ProductID, Name FROM Production.Product WHERE Color IN ('Multi', 'Silver') ORDER BY ProductID;
模式匹配(LIKE 和 NOT LIKE)
SELECT ProductID, Name FROM Production.Product WHERE Name LIKE 'Ch%' ORDER BY ProductID;
 like通配符
like通配符使用通配符时应着重考虑对性能的影响。如果表达式以通配符开头,则无法使用索引。(正如在电话簿中进行查找一样,如果所给的名称是“%mith”,而不是“Smith”,那么您将不知道需从电话簿的何处开始搜索。)如果通配符位于表达式内部或位于表达式末尾,则可以使用索引。
Null 值(IS NULL 和 IS NOT NULL)
SELECT s.Name FROM Sales.Customer c JOIN Sales.Store s ON c.CustomerID = s.CustomerID WHERE c.CustomerID IS NOT NULL ORDER BY s.Name;
比较 null 值时请谨慎从事。例如,指定 = NULL 与指定 IS NULL 是不同的。
所有记录(=ALL、>ALL、<= ALL、ANY)
-- 从其中已发货的产品量大于任何已发货的 H 类产品量的 SalesOrderDetail 表中检索订单和产品 ID SELECT OrdD1.SalesOrderID, OrdD1.ProductID FROM Sales.SalesOrderDetail OrdD1 WHERE OrdD1.OrderQty > ALL (SELECT OrdD2.OrderQty FROM Sales.SalesOrderDetail OrdD2 JOIN Production.Product Prd ON OrdD2.ProductID = Prd.ProductID WHERE Prd.Class = 'H');
条件的组合(AND、OR、NOT)
SELECT ProductID, Name FROM Production.Product WHERE ListPrice < 500 OR (Class = 'L' AND ProductLine = 'S');
4.7.1. 搜索通配符字符¶
当可以搜索通配符字符。有两种方法可指定平常用作通配符的字符:
使用 ESCAPE 关键字定义转义符。在模式中,当转义符置于通配符之前时,该通配符就解释为普通字符。例如,若要搜索字符串中所有的字符串 5%,请使用:
 sql_like
sql_like将通配符放在方括号 ([ ]) 中。若要搜索连字符 (-) 而不是使用它指定搜索范围,请将连字符作为方括号内的第一个字符:
SELECT ColumnA FROM your_table WHERE ColumnA LIKE '9[-]5';
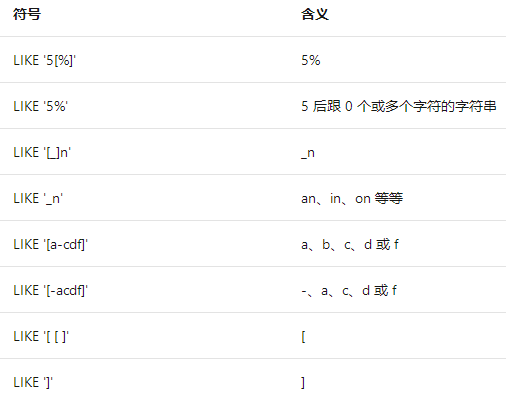 通配符转义
通配符转义
4.8. ORDER BY 排序¶
ORDER BY 子句按一列或多列(最多 8,060 个字节)对查询结果进行排序。
从 SQL Server 2005 开始,SQL Server 允许在 FROM 子句中指定对 SELECT 列表中未指定的表中的列进行排序。
ORDER BY 子句中引用的列名必须明确地对应于 SELECT 列表中的列或 FROM 子句中的表中的列。如果列名已在 SELECT 列表中有了别名,则 ORDER BY 子句中只能使用别名。同样,如果表名已在 FROM 子句中有了别名,则 ORDER BY 子句中只能使用别名来限定它们的列。
排序可以是升序的 (ASC),也可以是降序的 (DESC)。默认为 ASC。
如果 ORDER BY 子句中指定了多个列,则排序是嵌套的。
无法对数据类型为 text、ntext、image 或 xml 的列使用 ORDER BY。
ORDER BY 子句的准确结果取决于被排序的列的排序规则。对于 char、varchar、nchar 和 nvarchar 列,可以指定 ORDER BY 操作按照表或视图中定义的列的排序规则之外的排序规则执行。可以指定 Windows 排序规则名称或 SQL 排序规则名称。
-- 使用 Traditional_Spanish 排序规则 SELECT LastName FROM Person.Person ORDER BY LastName COLLATE Traditional_Spanish_ci_ai ASC;
4.9. 子查询 subquery¶
子查询是一个嵌套在 SELECT、INSERT、UPDATE 或 DELETE 语句或其他子查询中的查询。任何允许使用表达式的地方都可以使用子查询。
子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
有三种基本的子查询。它们是:
- 在通过 IN 或由 ANY 或 ALL 修改的比较运算符引入的列表上操作。 WHERE expression [NOT] IN (subquery)
- 通过未修改的比较运算符引入且必须返回单个值。 WHERE expression comparison_operator [ANY | ALL] (subquery)
- 通过 EXISTS 引入的存在测试。 WHERE [NOT] EXISTS (subquery)
许多包含子查询的 Transact-SQL 语句都可以改用联接表示。其他问题只能通过子查询提出。
在 Transact-SQL 中,包含子查询的语句和语义上等效的不包含子查询的语句(即联接的方式)在性能上通常没有差别。但是,在一些必须检查存在性的情况中,使用联接会产生更好的性能。否则,为确保消除重复值,必须为外部查询的每个结果都处理嵌套查询。所以在这些情况下,联接方式会产生更好的效果。
子查询的 SELECT 查询总是使用圆括号括起来。它不能包含 COMPUTE 或 FOR BROWSE 子句,如果同时指定了 TOP 子句,则只能包含 ORDER BY 子句。
子查询受下列限制的制约:
- 通过比较运算符引入的子查询选择列表只能包括一个表达式或列名称(对 SELECT * 执行的 EXISTS 或对列表执行的 IN 子查询除外)。
- 如果外部查询的 WHERE 子句包括列名称,它必须与子查询选择列表中的列是联接兼容的。
- ntext、text 和 image 数据类型不能用在子查询的选择列表中。
- 由于必须返回单个值,所以由未修改的比较运算符(即后面未跟关键字 ANY 或 ALL 的运算符)引入的子查询不能包含 GROUP BY 和 HAVING 子句。
- 包含 GROUP BY 的子查询不能使用 DISTINCT 关键字。
- 不能指定 COMPUTE 和 INTO 子句。
- 只有指定了 TOP 时才能指定 ORDER BY。
- 不能更新使用子查询创建的视图。
- 按照惯例,由 EXISTS 引入的子查询的选择列表有一个星号 (*),而不是单个列名。因为由 EXISTS 引入的子查询创建了存在测试并返回 TRUE 或 FALSE 而非数据,所以其规则与标准选择列表的规则相同。
4.10. 联接 join¶
通过联接,可以从两个或多个表中根据各个表之间的逻辑关系来检索数据。
联接条件可通过以下方式定义两个表在查询中的关联方式:
- 指定每个表中要用于联接的列。典型的联接条件在一个表中指定一个外键,而在另一个表中指定与其关联的键。
- 指定用于比较各列的值的逻辑运算符(例如 = 或 <>)。
可以在 FROM 或 WHERE 子句中指定内部联接;而只能在 FROM 子句中指定外部联接。联接条件与 WHERE 和 HAVING 搜索条件相结合,用于控制从 FROM 子句所引用的基表中选定的行。
比如下列联接因为是内部联接,因此也可以改写为在WHERE条件中指定联接。
-- FROM中指定联接(首选)
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > 10
AND Name LIKE N'F%';
-- WHERE中指定联接
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.VendorID = v.VendorID
AND StandardPrice > 10
AND Name LIKE N'F%';
在 FROM 子句中指定联接条件有助于将这些联接条件与 WHERE 子句中可能指定的其他任何搜索条件分开,建议用这种方法来指定联接。简化的 ISO FROM 子句联接语法如下:
FROM first_table
join_type
second_table
[ON (join_condition)]
join_type 指定要执行的联接类型
内部联接(典型的联接运算,使用类似于 = 或 <> 的比较运算符)。内部联接包括同等联接和自然联接。
外部联接。外部联接可以是左向外部联接、右向外部联接或完整外部联接。
在 FROM 子句中可以用下列某一组关键字来指定外部联接:
LEFT JOIN 或 LEFT OUTER JOIN。
左向外部联接的结果集包括 LEFT OUTER 子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某一行在右表中没有匹配行,则在关联的结果集行中,来自右表的所有选择列表列均为空值。
RIGHT JOIN 或 RIGHT OUTER JOIN
右向外部联接是左向外部联接的反向联接。将返回右表的所有行。如果右表的某一行在左表中没有匹配行,则将为左表返回空值。
FULL JOIN 或 FULL OUTER JOIN
完整外部联接将返回左表和右表中的所有行。当某一行在另一个表中没有匹配行时,另一个表的选择列表列将包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
交叉联接
交叉联接将返回左表中的所有行。左表中的每一行均与右表中的所有行组合。交叉联接也称作笛卡尔积。
join_condition 定义用于对每一对联接行进行求值的谓词(比较运算符或关系运算符)。
当 SQL Server 处理联接时,查询引擎会从多种可行的方法中选择最有效的方法来处理联接。由于各种联接的实际执行过程会采用多种不同的优化,因此无法可靠地预测。
4.11. UNION运算符¶
UNION 运算符可以将两个或多个 SELECT 语句的结果组合成一个结果集。
UNION 的结果集列名与 UNION 运算符中第一个 SELECT 语句的结果集中的列名相同。另一个 SELECT 语句的结果集列名将被忽略。
默认情况下,UNION 运算符将从结果集中删除重复的行。如果使用 ALL (即UNION ALL)关键字,那么结果中将包含所有行而不删除重复的行。
使用 UNION 运算符时需遵循下列准则:
在用 UNION 运算符组合的语句中,所有选择列表中的表达式(如列名称、算术表达式、聚合函数等)数目必须相同。
用 UNION 组合的结果集中的对应列或各个查询中所使用的任何部分列都必须具有相同的数据类型,并且可以在两种数据类型之间进行隐式数据转换,或者可以提供显式转换。例如,datetime 数据类型的列和 binary 数据类型的列之间的 UNION 运算符将不执行运算,直到进行了显式转换。但是,money 数据类型的列和 int 数据类型的列之间的 UNION 运算符将执行运算,因为它们可以进行隐式转换。
用 UNION 运算符组合的各语句中对应结果集列的顺序必须相同,因为 UNION 运算符按照各个查询中给定的顺序一对一地比较各列。
表中通过 UNION 运算所得到的列名称是从 UNION 语句中的第一个单独查询得到的。若要用新名称引用结果集中的某列(例如在 ORDER BY 子句中),必须按第一个 SELECT 语句中的方式引用该列
SELECT city AS Cities FROM stores_west UNION SELECT city FROM stores_east ORDER BY city
4.12. EXCEPT和INTERSECT半联接¶
使用 EXCEPT 和 INTERSECT 运算符可以比较两个或更多 SELECT 语句的结果并返回非重复值。
- EXCEPT 运算符返回由 EXCEPT 运算符左侧的查询返回、而又不包含在右侧查询所返回的值中的所有非重复值。(左边结果与 左右两边结果的交集的差集 A-A∩B)
- INTERSECT 返回由 INTERSECT 运算符左侧和右侧的查询都返回的所有非重复值。(两个查询结果的交集然后去重后的结果,A∩B)
使用 EXCEPT 或 INTERSECT 比较的结果集必须具有相同的结构。它们的列数必须相同,并且相应的结果集列的数据类型必须兼容。
INTERSECT 运算符优先于 EXCEPT。
4.13. 公用表表达式 WITH¶
公用表表达式 (CTE) 可以认为是在单个 SELECT、INSERT、UPDATE、DELETE 或 CREATE VIEW 语句的执行范围内定义的临时结果集。CTE 与派生表类似,具体表现在不存储为对象,并且只在查询期间有效。与派生表的不同之处在于,CTE 可自引用,还可在同一查询中引用多次。
CTE 可用于:
- 创建递归查询。
- 在不需要常规使用视图时替换视图,也就是说,不必将定义存储在元数据中。
- 启用按从标量嵌套 select 语句派生的列进行分组,或者按不确定性函数或有外部访问的函数进行分组。
- 在同一语句中多次引用生成的表。
使用 CTE 可以获得提高可读性和轻松维护复杂查询的优点。查询可以分为单独块、简单块、逻辑生成块。之后,这些简单块可用于生成更复杂的临时 CTE,直到生成最终结果集。
可以在用户定义的例程(如函数、存储过程、触发器或视图)中定义 CTE。
CTE 由表示 CTE 的表达式名称、可选列列表和定义 CTE 的查询组成。定义 CTE 后,可以在 SELECT、INSERT、UPDATE 或 DELETE 语句中对其进行引用,就像引用表或视图一样。CTE 也可用于 CREATE VIEW 语句,作为定义 SELECT 语句的一部分。
CTE 的基本语法结构如下:
WITH expression_name [ ( column_name [,...n] ) ]
AS
( CTE_query_definition )
-- 运行 CTE 的语句
SELECT <column_list>
FROM expression_name;
-- 定义 CTE 查询别名和列名称
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- 定义CTE查询的结果集
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- 使用CTE查询的结果进行进一步的查询
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;